Students will gain a better understanding of how to use pandas for manipulating data frames
Specific coding skills learned: - Subsetting data frames - Joining data frames together - Other useful pandas functions (incuding groupby, statistics, and conditional subsetting)
%pip install pandas %pip install matplotlib %pip install numpy import pandas as pd import matplotlib.pyplot as pltimport numpy as np
In our last class, we discussed the basics of how to use pandas to read in our data. When we load in data from a CSV file with Pandas using a function such as reas_csv, we get a data structure known as a data frame. Basically, this is a two-dimensional table of rows and columns.
This is useful in terms of allowing us to visualize our data, but most users will want to utilize the data for their own research purposes. Therefore, users will find it helpful to use pandas as an application programming interface (or API), which is basically a set of functions that allow users access to the features of the data.
For this class, we are going to be using daily weather history data from multiple U.S. cities from July 2014 - June 2015 (downloaded from FiveThirtyEight’s public repository of data found here: https://github.com/fivethirtyeight/data/tree/master/us-weather-history).
The first set of data we are going to read in is from Philadelphia.
The rows of this data frame represent each day during this period, and the columns represent the weather data that has been collected.
As you can see, there are numerous types of data that has been collected, including the temperatures that occurred that day, what the average temperatures have been for that day over the years, the records for that day, and the amount of precipitation that occurred both on that day and on average for that day.
Question 1: Let’s say that you do not care about the temperature data, so most of these columns are not neccessary. How can you get the data you want to have?
Answer: You can subset the data frame to only contain the columns you need
In pandas, one of the ways you can select certain subsets of the data is to specify them by the row and/or column names.
To select a particular column (for example, the actual preciptation for each day) , you use square brackets [] along with the column name of the column of interest in quotation marks. Alternatively, this is known as “slicing”, since you are taking a slice of the original data frame.
In order to get both columns of precipitation data, we need to use double brackets, then within the brackets we list the columns of interest with a comma between them, as shown below.
Another way of selecting these columns is to add to the end of our data frame object “.loc” (which looks for the names of the columns by labels). Since our matrix is rows by columns, the “:” symbol tells the computer that we want all of the rows, but only the columns with specific labels.
Likewise, we can do the same for the rows, only placing the “:” after the comma (in the columns position), and selecting the rows by label before the comma, as shown below.
philly_weather.loc[["2014-7-1"],:]
actual_mean_temp
actual_min_temp
actual_max_temp
average_min_temp
average_max_temp
record_min_temp
record_max_temp
record_min_temp_year
record_max_temp_year
actual_precipitation
average_precipitation
record_precipitation
date
2014-7-1
83
72
93
68
86
52
102
1988
1901
0.0
0.13
1.04
philly_weather.loc[["2014-7-1","2014-7-2"],:]
actual_mean_temp
actual_min_temp
actual_max_temp
average_min_temp
average_max_temp
record_min_temp
record_max_temp
record_min_temp_year
record_max_temp_year
actual_precipitation
average_precipitation
record_precipitation
date
2014-7-1
83
72
93
68
86
52
102
1988
1901
0.00
0.13
1.04
2014-7-2
86
75
96
68
86
52
103
1965
1901
0.21
0.13
1.73
While this is not too difficult if we only need a handful of rows and/or columns, this could become time-consuming if we want to get a series of rows and/or columns.
Question 2: Instead of using the labels of the rows/columns, what is another attribute you can use to subset the data?
Answer: You can use their numerical location (ex: the 1st row or 2nd column)
A little earlier in the lesson, we used “.loc” to select rows and columns by their label. To do this by their index, we can instead use “.iloc” to select the row and/or column index value(s).
Given that the “actual_precipitation” and “average_precipitation” columns represent the 9th through 11th rows respectively, this is how we subset the data to obtain the values in these columns .
(note: the first piece of code means “select the data from the 9th column up to, but not including, the 12th column”).
philly_weather.iloc[:,9:12]
actual_precipitation
average_precipitation
record_precipitation
date
2014-7-1
0.00
0.13
1.04
2014-7-2
0.21
0.13
1.73
2014-7-3
0.09
0.12
3.66
2014-7-4
0.04
0.13
2.08
2014-7-5
0.00
0.13
4.38
...
...
...
...
2015-6-26
0.00
0.12
2.77
2015-6-27
1.34
0.10
3.27
2015-6-28
0.22
0.11
2.48
2015-6-29
0.00
0.12
4.62
2015-6-30
1.50
0.12
1.56
365 rows × 3 columns
philly_weather.iloc[0:2,:]
actual_mean_temp
actual_min_temp
actual_max_temp
average_min_temp
average_max_temp
record_min_temp
record_max_temp
record_min_temp_year
record_max_temp_year
actual_precipitation
average_precipitation
record_precipitation
date
2014-7-1
83
72
93
68
86
52
102
1988
1901
0.00
0.13
1.04
2014-7-2
86
75
96
68
86
52
103
1965
1901
0.21
0.13
1.73
If the numbers are not in a sequence (ex: columns 0, 5, and 7), you can get the subset of the data like this
philly_weather.iloc[:,[0,5,7]]
actual_mean_temp
record_min_temp
record_min_temp_year
date
2014-7-1
83
52
1988
2014-7-2
86
52
1965
2014-7-3
83
54
1957
2014-7-4
73
52
1986
2014-7-5
74
55
1963
...
...
...
...
2015-6-26
76
51
1960
2015-6-27
67
50
1965
2015-6-28
73
54
1961
2015-6-29
72
52
1888
2015-6-30
77
52
1988
365 rows × 3 columns
Joining Data Frames
Of course, we might not only be interested in the data from one city. Imagine that we want to do side-by-side comparisons of the average precipitation in Seattle vs. Philadelphia.
Let’s first read in the weather pattern data for Seattle as well.
Rather than having to flip between both data frames, we can instead combine them into one separate data frame using the function “join”.
There are four different ways that we can join our data, which we will go through below: “left”, “right”, “inner”, and “outer”
For the sake of an example, let us sort our data such that Philadelphia’s precipitation data is sorted by the lowest to highest record precipitation, while Seattle’s precipitation data is sorted from the highest to lowest record precipitation.
A left join indicates that we preserve the order of the data frame is getting another data frame joined to it (in this case, the Philadelphia precipitation data). Since the suffix names are the same for both dataframes, we use lsuffix and rsuffix to specify which columns came from which dataframe.
(Note: ‘left’ is the default setting)
philly_weather_precip_reordered.join(seattle_weather_precip_reordered, how ='left', lsuffix ='_philly', rsuffix ='_seattle')
actual_precipitation_philly
average_precipitation_philly
record_precipitation_philly
actual_precipitation_seattle
average_precipitation_seattle
record_precipitation_seattle
date
2015-4-29
0.00
0.12
0.85
0.00
0.07
1.06
2014-10-13
0.02
0.10
0.90
0.30
0.10
0.66
2015-2-25
0.00
0.10
0.90
0.16
0.13
0.98
2015-3-9
0.00
0.11
0.94
0.00
0.12
1.47
2014-11-30
0.00
0.12
0.96
0.00
0.22
1.50
...
...
...
...
...
...
...
2014-8-13
0.00
0.11
5.21
0.85
0.03
0.85
2014-10-8
0.00
0.11
5.53
0.00
0.08
1.16
2014-8-3
0.23
0.12
5.63
0.00
0.01
0.47
2014-9-16
0.20
0.13
6.63
0.00
0.05
0.76
2014-7-28
0.23
0.14
8.02
0.00
0.02
0.22
365 rows × 6 columns
Likewise, a right join indicates that we preserve the order of the data frame that is being joined to the first data frame (in this case, the Seattle precipitation data).
philly_weather_precip_reordered.join(seattle_weather_precip_reordered, how ='right', lsuffix ='_philly', rsuffix ='_seattle')
actual_precipitation_philly
average_precipitation_philly
record_precipitation_philly
actual_precipitation_seattle
average_precipitation_seattle
record_precipitation_seattle
date
2014-10-20
0.00
0.10
2.72
0.46
0.12
5.02
2014-12-3
0.11
0.12
1.60
0.00
0.20
3.77
2014-11-20
0.00
0.10
2.59
0.14
0.23
3.41
2014-11-6
0.52
0.09
1.41
0.16
0.21
3.29
2015-2-8
0.00
0.09
1.15
0.14
0.13
3.06
...
...
...
...
...
...
...
2014-7-11
0.00
0.14
1.92
0.00
0.03
0.25
2014-7-28
0.23
0.14
8.02
0.00
0.02
0.22
2014-7-29
0.00
0.14
3.53
0.00
0.02
0.17
2014-8-8
0.00
0.12
4.40
0.00
0.02
0.13
2014-7-15
0.81
0.15
2.96
0.00
0.02
0.11
365 rows × 6 columns
If we want to order the dates lexographically, we can change the how parameter to ‘outer’ (or the union of the datasets).
philly_weather_precip_reordered.join(seattle_weather_precip_reordered, how ='outer', lsuffix ='_philly', rsuffix ='_seattle')
actual_precipitation_philly
average_precipitation_philly
record_precipitation_philly
actual_precipitation_seattle
average_precipitation_seattle
record_precipitation_seattle
date
2014-10-1
0.00
0.11
3.00
0.00
0.07
0.56
2014-10-10
0.00
0.11
2.10
0.01
0.09
1.02
2014-10-11
0.48
0.10
2.04
0.29
0.09
0.89
2014-10-12
0.00
0.11
1.62
0.00
0.09
0.70
2014-10-13
0.02
0.10
0.90
0.30
0.10
0.66
...
...
...
...
...
...
...
2015-6-5
0.13
0.13
2.31
0.00
0.06
0.63
2015-6-6
0.05
0.12
1.95
0.00
0.06
1.54
2015-6-7
0.00
0.13
3.50
0.00
0.06
0.81
2015-6-8
0.88
0.12
2.00
0.00
0.07
0.81
2015-6-9
0.02
0.12
2.03
0.00
0.06
0.72
365 rows × 6 columns
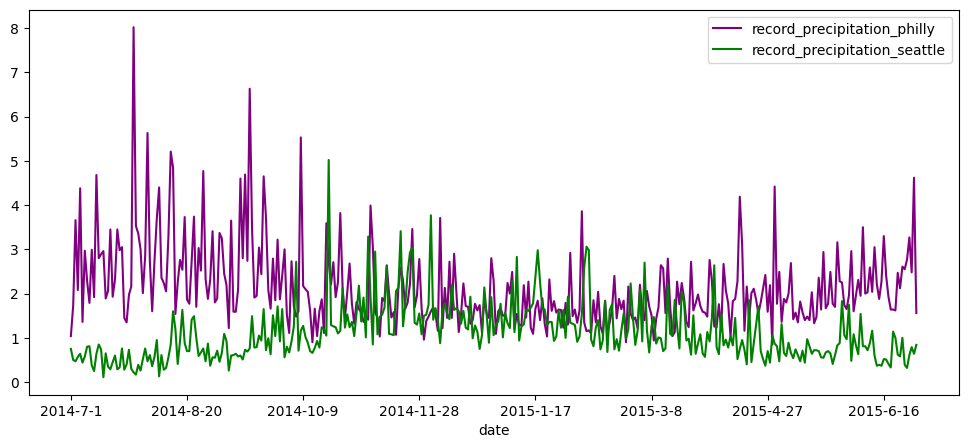
When we combine these datasets together, we can easily compare data from both data frames, for example plotting the record precipitation in Seattle vs. Philadelphia
all_precipitation = philly_weather_precip.join(seattle_weather_precip,lsuffix ='_philly', rsuffix ='_seattle')ax = plt.gca()all_precipitation.plot(kind='line',y='record_precipitation_philly',ax=ax, color ='purple',figsize=(12,5))all_precipitation.plot(kind='line',y='record_precipitation_seattle',ax=ax, color ='green',figsize=(12,5))plt.show()
Let us pretend that we want to add information about each month (stored in the months object)
Now, let us say that in addition to the rainfall data, we also started to collect information about the average dewpoint on each day for the first three months in Philadelphia. However, due to statewide budget cuts scientists could not afford to gather data for the rest of the year.
As done previously, we can join the datasets together, but you will notice below that all of the dates where there was no dewpoint recorded are labeled ‘NaN’ (“Not a number”, or undefined, data points).
philly_weather_precip.join(dewpoint)
actual_precipitation
average_precipitation
record_precipitation
dewpoint
date
2014-7-1
0.00
0.13
1.04
47.0
2014-7-2
0.21
0.13
1.73
59.0
2014-7-3
0.09
0.12
3.66
67.0
2014-7-4
0.04
0.13
2.08
41.0
2014-7-5
0.00
0.13
4.38
45.0
...
...
...
...
...
2015-6-26
0.00
0.12
2.77
NaN
2015-6-27
1.34
0.10
3.27
NaN
2015-6-28
0.22
0.11
2.48
NaN
2015-6-29
0.00
0.12
4.62
NaN
2015-6-30
1.50
0.12
1.56
NaN
365 rows × 4 columns
What if you only want to keep the values where dewpoints are recorded? To do this, you can use join with the how parameter set to ‘inner’ (or intersection of the data), as shown below.
philly_weather_precip.join(dewpoint, how='inner')
actual_precipitation
average_precipitation
record_precipitation
dewpoint
date
2014-7-1
0.00
0.13
1.04
47
2014-7-2
0.21
0.13
1.73
59
2014-7-3
0.09
0.12
3.66
67
2014-7-4
0.04
0.13
2.08
41
2014-7-5
0.00
0.13
4.38
45
...
...
...
...
...
2014-9-26
0.00
0.13
2.79
46
2014-9-27
0.00
0.14
1.85
65
2014-9-28
0.00
0.13
3.22
51
2014-9-29
0.00
0.14
1.87
68
2014-9-30
0.00
0.13
2.41
59
92 rows × 4 columns
Other useful pandas functions: conditional subsetting
There are other ways to subset datasets by their index or their rownames/colnames.
Let us say that you are only looking for days where the max temperature was greater than 90. How would we be able to get only those rows?
To do this, we can do something called conditional subsetting.
Remember in lesson 1 when we learned about comparisons, such as “greater than” ( > ), “lesser than” ( < ), “equals” (==)? We can subset our data this way as well.
To pick the rows where the max temperature was greater than 90, we can subset the data as follows
Let us go back to to the all_precip_wmonths object, when we added information about which month each day was in for the combined Philly and Seattle precipitation data. One neat thing we can do is to group data based on certain column values (such as months), as shown below.
all_precip_wmonths.groupby(["months"])
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[26], line 1----> 1all_precip_wmonths.groupby(["months"])
NameError: name 'all_precip_wmonths' is not defined
We can do functions such as mean, min, and max for each month, rather than every day.
all_precip_wmonths.groupby(["months"]).mean()
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[27], line 1----> 1all_precip_wmonths.groupby(["months"]).mean()
NameError: name 'all_precip_wmonths' is not defined
all_precip_wmonths.groupby(["months"]).min()
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[28], line 1----> 1all_precip_wmonths.groupby(["months"]).min()
NameError: name 'all_precip_wmonths' is not defined
all_precip_wmonths.groupby(['months']).max()
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[29], line 1----> 1all_precip_wmonths.groupby(['months']).max()
NameError: name 'all_precip_wmonths' is not defined
Remember when we plotted the record precipitation in Philadelphia vs. Seattle? What if we instead plotted the mean month-to-month instead of daily?
mean_months_precip = all_precip_wmonths.groupby(["months"]).mean()ax2 = plt.gca()mean_months_precip.plot(kind='line',y='record_precipitation_philly',ax=ax2, color ='purple',figsize=(12,5))mean_months_precip.plot(kind='line',y='record_precipitation_seattle',ax=ax2, color ='green',figsize=(12,5))plt.show()
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[30], line 1----> 1 mean_months_precip = all_precip_wmonths.groupby(["months"]).mean()
2 ax2 = plt.gca()
3 mean_months_precip.plot(kind='line',y='record_precipitation_philly',ax=ax2, color = 'purple',figsize=(12,5))
NameError: name 'all_precip_wmonths' is not defined
From this graph, we can see that months where the record precipitation was on average the highest in Philadelphia (such as August and July) are the lowest precipitation times in Seattle!
Other useful pandas functions: statistics
Lastly, we can perform statistics on our data as a whole. We have already gone through how certain mathematical functions such as min, max, or mean can be calculated on different groups, but this can also be done to columns of the data frame as well.
For example, we can get the mean value of the actual precipitation in Seattle and Philadelphia, as shown below:
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[31], line 1----> 1all_precip_wmonths["actual_precipitation_seattle"].mean()
NameError: name 'all_precip_wmonths' is not defined
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[32], line 1----> 1all_precip_wmonths["actual_precipitation_philly"].mean()
NameError: name 'all_precip_wmonths' is not defined
As you can see, on average the daily precipitation in Philadelphia is only 0.02 inches greater than Seattle.
If you wanted to look at both at the same time, we follow the same rules that we did in label-based subsetting:
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[33], line 1----> 1all_precip_wmonths[["actual_precipitation_seattle","actual_precipitation_philly"]].mean()
NameError: name 'all_precip_wmonths' is not defined
In general, if you wanted to look at multiple statistics at once, you can call the function ‘describe’, as shown below:
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[34], line 1----> 1all_precip_wmonths[["actual_precipitation_seattle","actual_precipitation_philly"]].describe()
NameError: name 'all_precip_wmonths' is not defined
In-class exercises
In-class exercise 1: How would we select the precipitation data from July 1st and July 2nd, 2014, in Philadelphia, using label-based subsetting?
Answer:
In-class exercise 2: What would we do to only select the precipitation data from July 1st and July 2nd, 2014 using index-based subsetting?
Answer:
In-class exercise 3: Using the ‘all_precipitation’ and ‘months’ objects called earlier, how can we join these dataframes together and save it as a new object titled ‘all_precip_wmonths’?
Answer:
In-class exercise 4: Go back and use the philly_weather and seattle_weather objects to figure out which days had a record minimum tempeature under 10 in either dataset
Answer:
In-class exercise 5: Using the all_precip_wmonths object, how would you find the differences in standard deviation in average precipitation between Philadelphia and Seattle for each month? (Hint: you may want to use the pandas function “values” at some point in this answer)
Answer:
Homework
There are 81 different exercises pertaining to manipulating Pandas data frames found here: https://www.w3resource.com/python-exercises/pandas/index-dataframe.php (with the predicted output as well as possible solutions to the problems).
I would suggest doing problems 3, 4, 5, 7, 9, 10, 12, 13, 14, 15, 24, and 31 (and if you have time/interest, problems 33, 44, 45, 49, and 52 are also good choices)