- The library is already synchronized with the lockfile.Applying Visualization Methods
Data Visualization, Day 2
Introduction
Welcome to Day 2 of our data visualization journey! Today, we’ll dive deeper into the world of visualizing data using the Palmer Penguins dataset. This dataset provides insights into penguins in the Palmer Archipelago, and it’s a perfect opportunity for us to practice and hone our visualization skills.
- This session is an opportunity to:
- Independently code visualizations.
- Learn how to troubleshoot issues that arise.
- Explore data in a hands-on manner.
- We will also teach several new data visualization tricks:
- Changing shapes of points.
- Customizing figure legends.
- Using
facet_gridfor comparing many aspects of data simultaneously. - Other advanced plotting tricks.
- Approach this session with curiosity and an adventurous spirit:
- Experiment with different plot types.
- Play with colors and styles.
- Let creativity guide your visual storytelling.
- Questions are welcome. Let’s make some pretty pictures!
 The Palmer Archipelago penguins. Artwork by @allison_horst.
The Palmer Archipelago penguins. Artwork by @allison_horst.
Objectives of Data Visualization: Class 2
Apply objectives from Class 1 to a new dataset
Create a plot from (almost) scratch, using tools (Google, Stack Overflow) to help you
Get a feel for the differences between creating plots in Base R and
ggplot.
Dataset Overview
First we load necessary packages. If the palmerpenguins package is not installed, we can install it by un-commenting “install.packages” below.
Tip – Suppress Package Startup Messages
The suppressPackageStartupMessages() function in R is used to prevent the display of startup messages when loading packages. This can make your R script output cleaner and more readable, especially when loading multiple packages.
suppressPackageStartupMessages(library(tidyverse))
#install.packages('palmerpenguins')
library(palmerpenguins)The dataset includes measurements of three penguin species: Adélie, Chinstrap, and Gentoo. The palmerpenguins package automatically loads the data into an object called penguins.
First we check the data class of penguins with class(), and take a look at the first few rows using head().
#what class is our data
class(penguins)[1] "tbl_df" "tbl" "data.frame"head(penguins)# A tibble: 6 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
sex year
<fct> <int>
1 male 2007
2 female 2007
3 female 2007
4 <NA> 2007
5 female 2007
6 male 2007As we can see, the dataset, which is a tibble/dataframe, contains many numerical (lengths, depths, and masses), and categorical (species, island, and sex) variables. It also contains a variable that could be categorical or numerical (year).
Exploratory Questions
In this section, we will take some time to ask questions about the Palmer Penguins dataset. Asking questions is a fundamental part of data analysis, as it guides our exploration and helps us uncover interesting patterns and insights.
Consider the different types of questions you might ask to learn more about this dataset. What questions can we answer using different data types, and what kind of plots might we use to answer them?
Some example questions
If you are having trouble of thinking of questions on your own, here are some example questions related to different combinations of numerical or categorical variables:
Questions leading to numerical by numerical plots
How does flipper length vary with body mass among different penguin species? This question explores correlations and possible factors influencing these traits.
Is there a relationship between the bill depth and flipper length, and does this relationship vary by species? This encourages explores multiple numerical variables and consider biological implications. Since we are comparing species, additional visualization tools like coloring points by species could aid or visualization.
Questions leading to categorical by numerical plot
How does the average body mass differ across penguin species? This question will lead to examining differences between groups.
Does the distribution of flipper lengths differ by the island on which the penguins were observed? This question could be answered by a visauization of several separate distributions, which could overlap with each other.
Questions related to one numerical variable
What is the distribution of bill lengths in the Palmer Penguins dataset, and what might this tell us about their feeding habits?
How are body mass values distributed within each species, and what does this suggest about the health or environment of these populations?
Questions related to multiple categorical variables
How do the relationships between body mass and flipper length change over different years of data collection?
Can we observe any noticeable trends in bill dimensions on different islands, and how do these trends compare across species?
These questions require the comparision of multiple categories of variables, and could be usefully displayed as separate plots side-by-side. We will use the tool facet_grid at the end of this lesson to approach such questions.
Making plots!
Warm up: numerical by numerical plots
To compare two numerical variables, a scatterplot is often the simplest and most effective plotting method. Here, we will compare the flipper length and body mass of our penguins. Remember, the inputs to a scatterplot are the columns of our tibble, which should be numeric, integer, or double vectors. Lets take a look at our data with head() and confirm the datatype with class().
head(penguins$flipper_length_mm)[1] 181 186 195 NA 193 190class(penguins$flipper_length_mm)[1] "integer"First we create a simple scatterplot with x and y labels in base r.
#simple ggplot plot with x and y axis labeled
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g,)) +
geom_point() +
labs(x = "Flipper Length (cm)", y = "Body Mass (kg)",
title = "Body Mass vs. Flipper Length")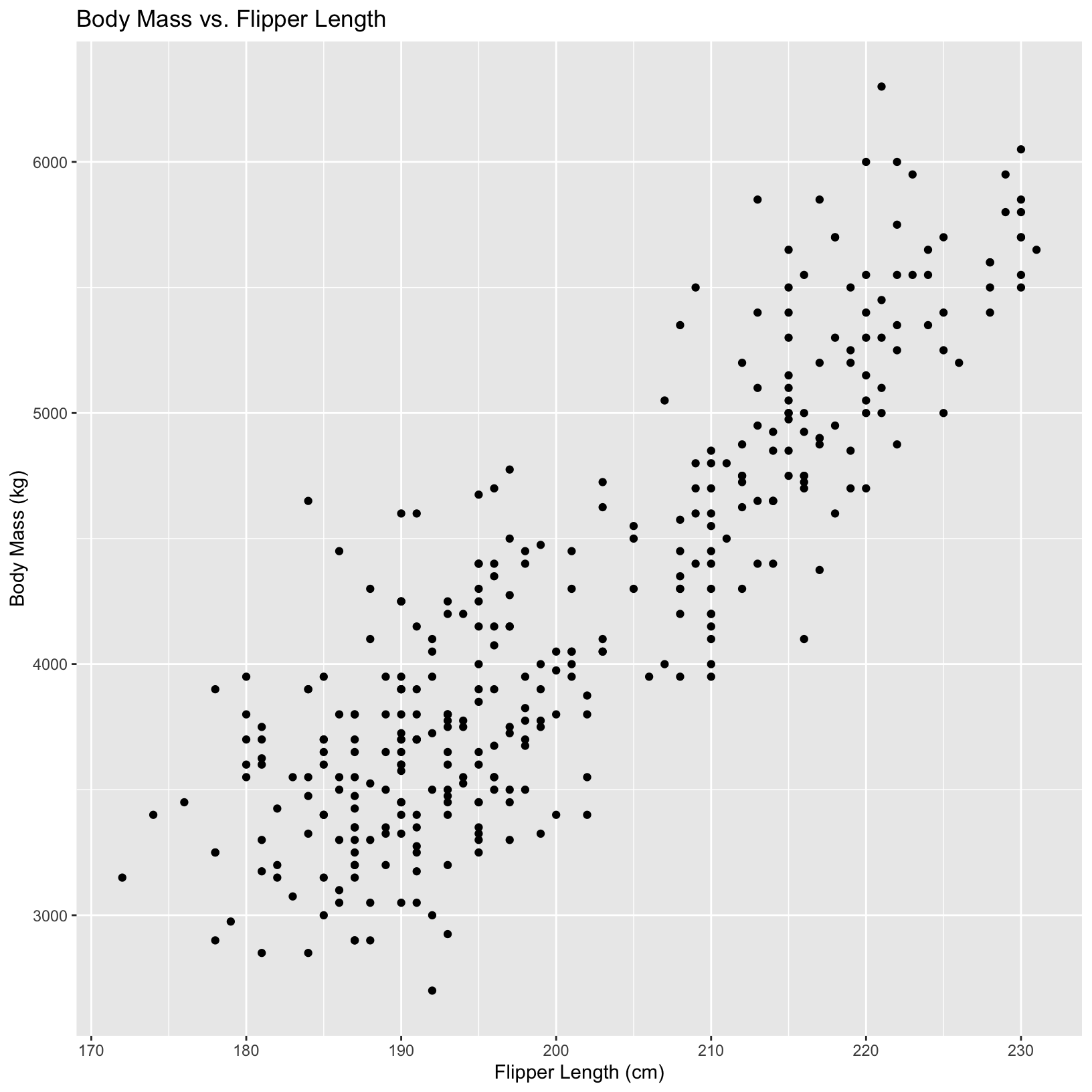
Can we compare different species in these plots? Let’s color our points based on the species.
# color dots by species
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g, color = species)) +
geom_point() +
labs(x = "Flipper Length (cm)", y = "Body Mass (kg)",
title = "Body Mass vs. Flipper Length",
color = "Species")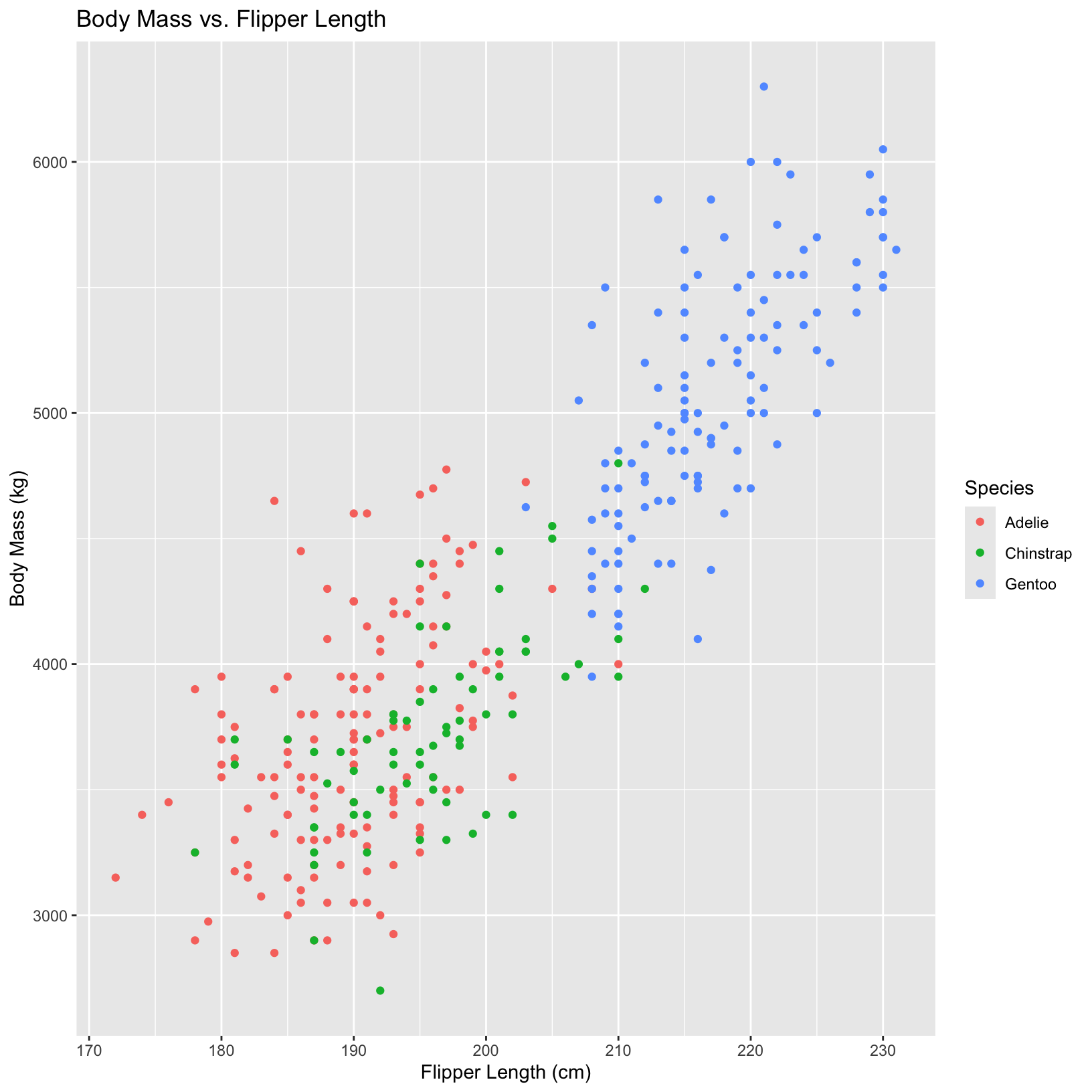
First we create a simple scatterplot with x and y labels in base r.
#simple base r plot with x and y axis labeled
plot(penguins$flipper_length_mm, penguins$body_mass_g,
xlab = "Flipper Length (mm)", ylab = "Body Mass (g)")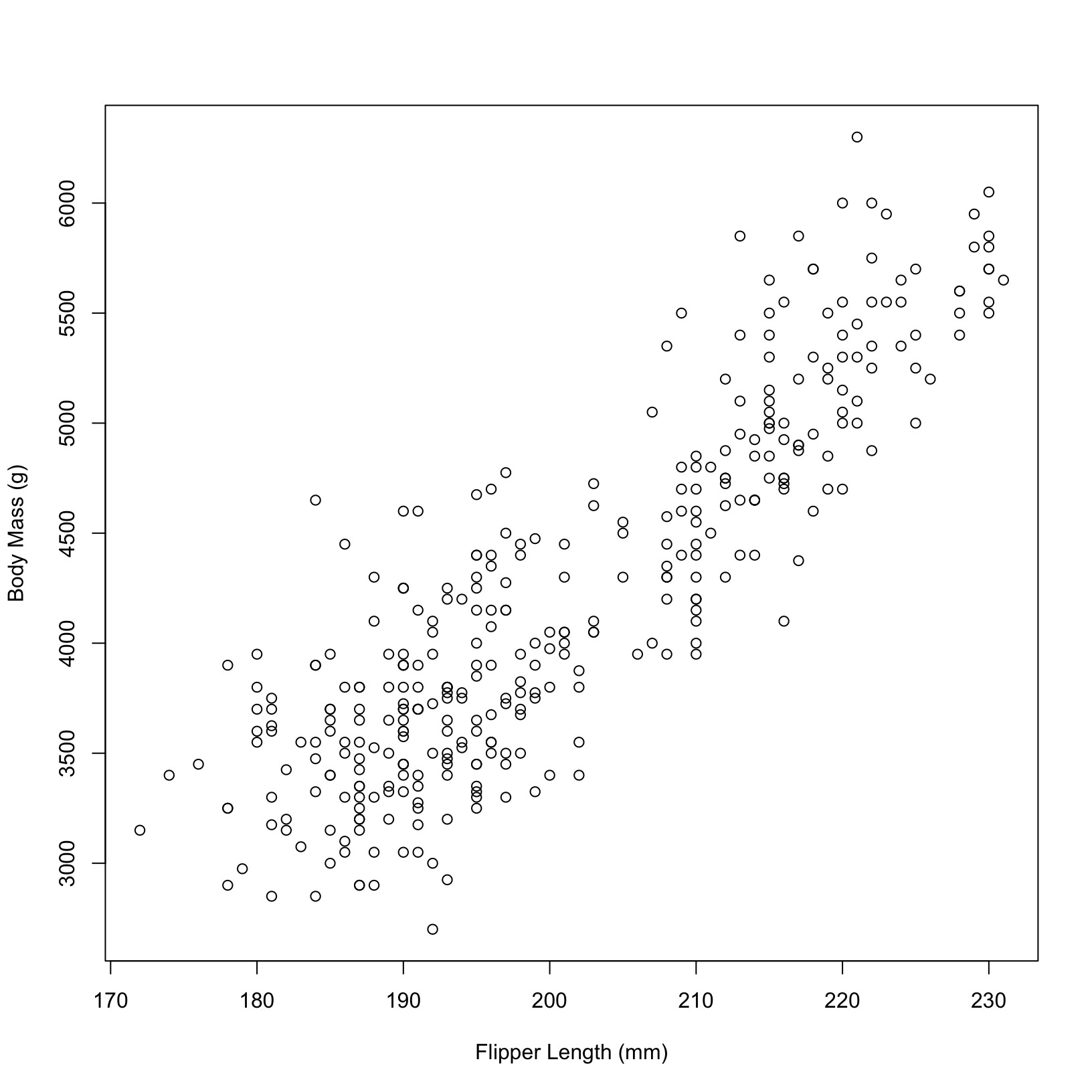
Can we compare different species in these plots? Let’s color our points based on the species.
# color dots by species
plot(penguins$flipper_length_mm, penguins$body_mass_g,
xlab = "Flipper Length (mm)", ylab = "Body Mass (g)",
col = penguins$species) 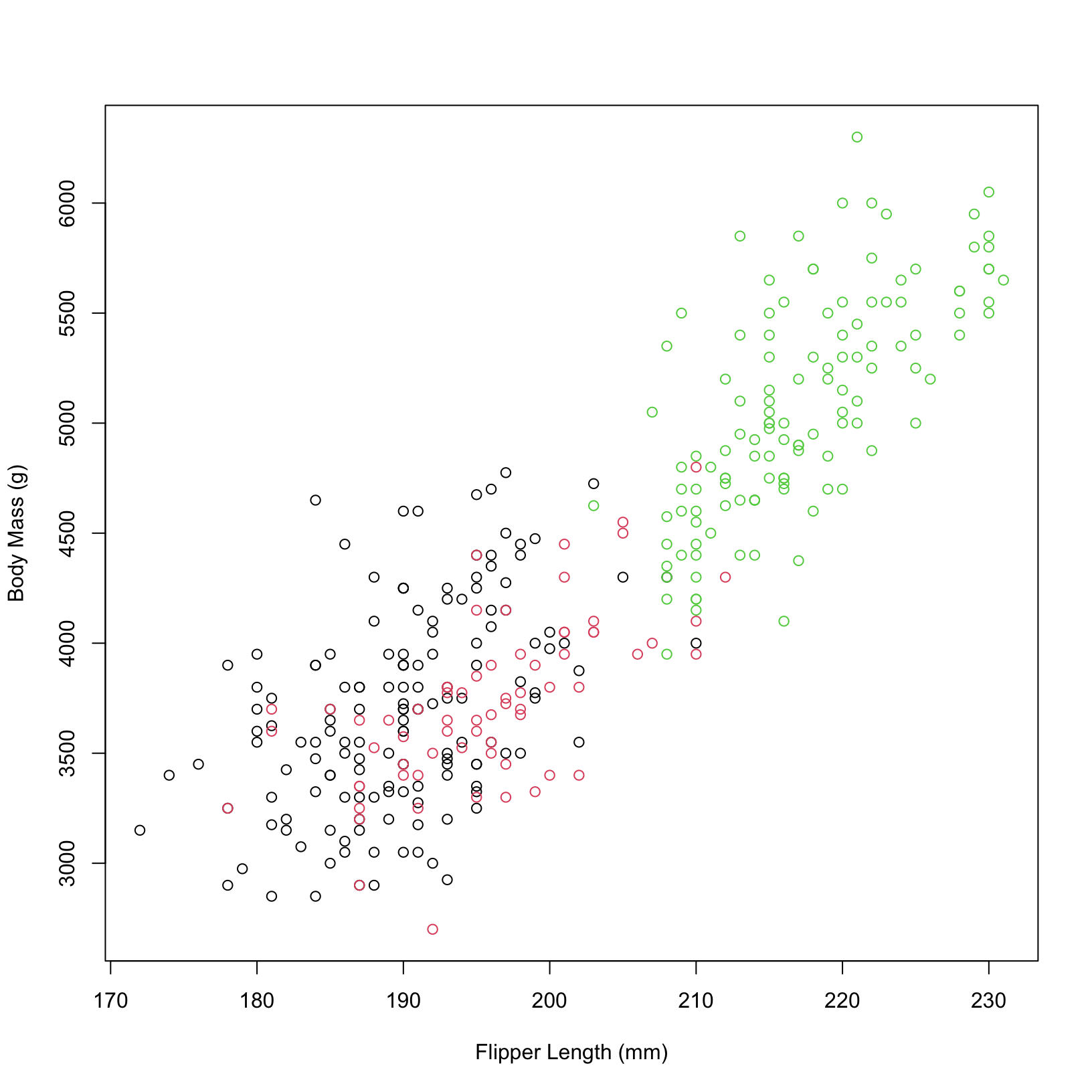
Why are colors specified differently in base R and ggplot?
In base R plotting, the color for each point is specified directly within the
plot()function using the col argument. This argument can take a vector of colors, which will be applied to the points in the plot. In this example, we are passing the species information directly to the col argument to color the points based on the species.In ggplot2, the aesthetics (aes) of the plot are defined within the
aes()function. The color aesthetic is specified inside theaes()function to map the species variable to the colors of the points. This approach follows the grammar of graphics philosophy, where data properties are mapped to visual properties in a structured way.Both methods allow us to compare different species in the plots by coloring the points based on the species. However, the ggplot2 approach is generally more flexible and powerful for creating complex visualizations.
Another way to change the colors in a ggplot–local aesthetics
In ggplot2, the aes() function is used to map data variables to visual properties (aesthetics) of the plot. The placement of the color specification can vary based on whether it is applied globally or locally.
Global aesthetics apply to all geoms in the plot, and are added in the initial
ggplot()call (or in a stand-aloneaes()layer).Local aesthetics apply only to the geom to which they are added.
This first plot produces the same output as our original plot.
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species)) +
labs(x = "Flipper Length (cm)", y = "Body Mass (kg)",
title = "Body Mass vs. Flipper Length",
color = "Species")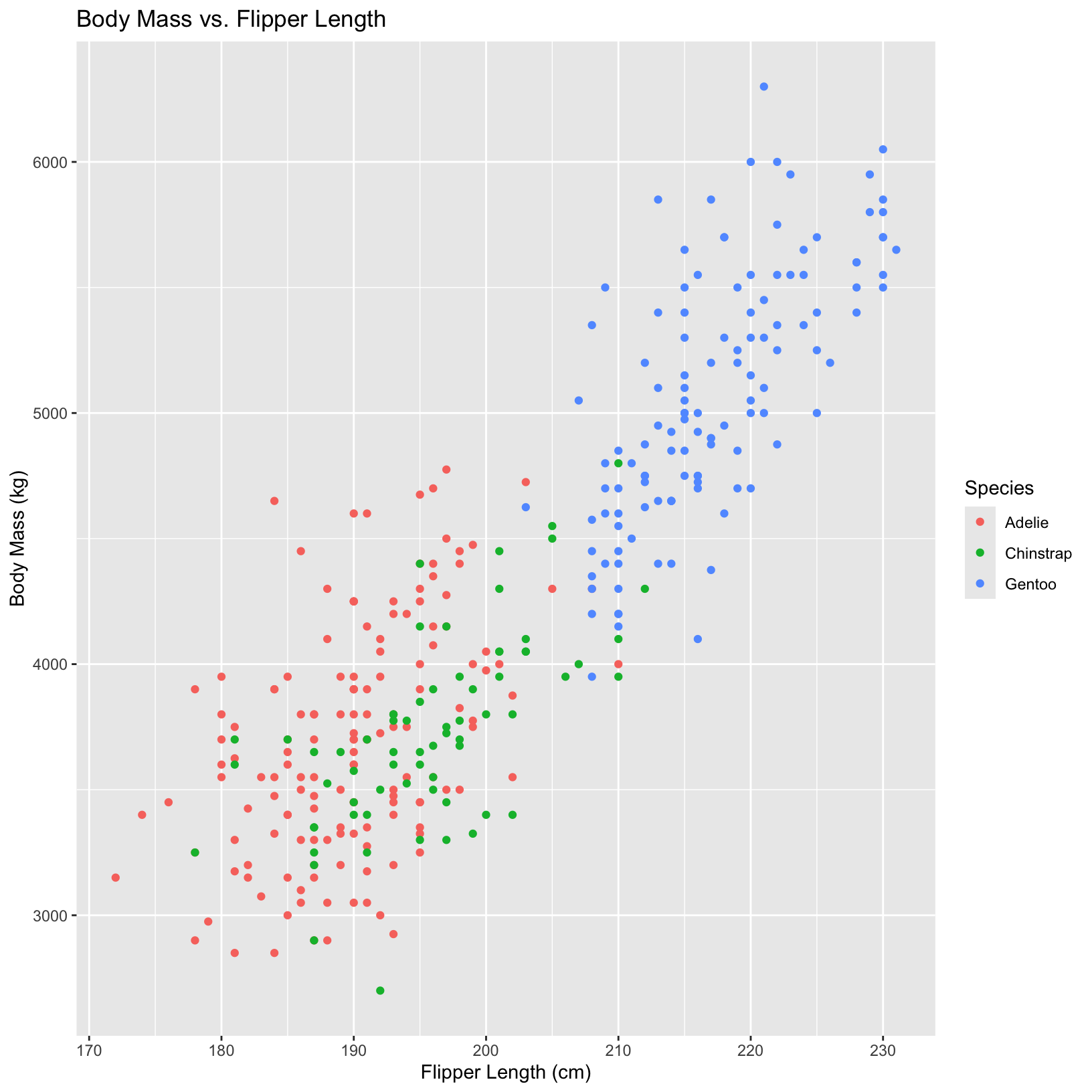
In this second plot, the local aesthetic overrides the global one.
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g, color = species)) +
geom_point(aes(color = flipper_length_mm)) + # local aesthetic applied here
labs(x = "Flipper Length (cm)", y = "Body Mass (kg)",
title = "Body Mass vs. Flipper Length",
color = "Species")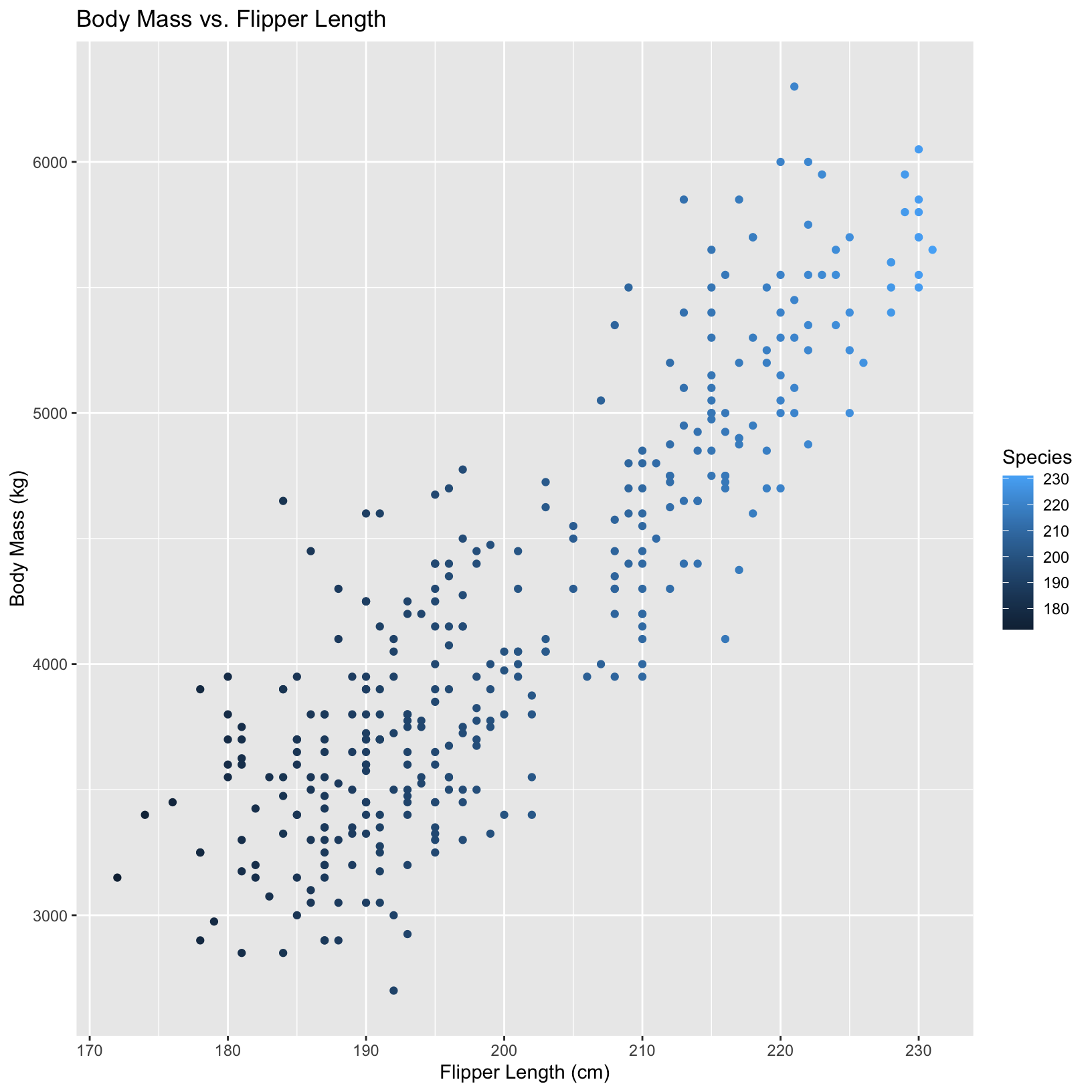
Let’s customize our plots!
Let’s customize these plots some more! Here we challenge you to change the shapes of the points for each species, add a customized legend in the position of the plot we want, and change the size of the points.
Take 5-10 minutes to try to figure out one or more of the changes we made to the plot:
- Change the shape of the points based on species.
- Add custom colors for the different species.
- Change the position of the legend to make it more visually pleasing.
- Add a subtitle to the figure.
Feel free to try ggplot or base R, depending on your preference. Practice finding this information using:
Use Google to find informative articles online like this
Ask a friend or instructor for help if you get stuck.
Feel free to add your own touches to the figure, and experiment with changing the numbers and variables in the figure!
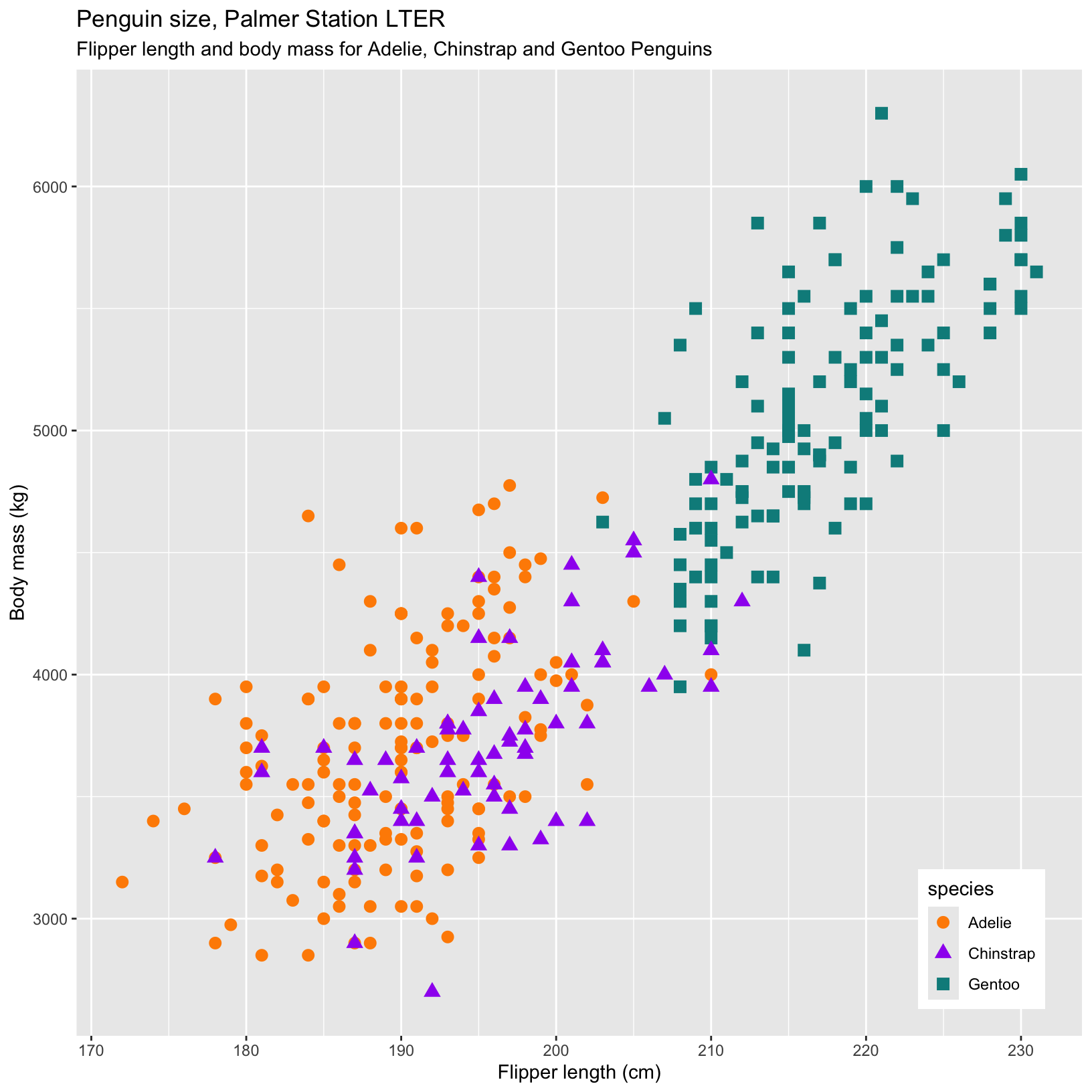
Code used to make the plot–try on your own first!
# Even more complex example with custom labels, colors, and fig legend position
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species), size = 3) +
scale_color_manual(values = c("darkorange","purple","cyan4")) +
labs(title = "Penguin size, Palmer Station LTER",
subtitle = "Flipper length and body mass for Adelie, Chinstrap and Gentoo Penguins",
x = "Flipper length (cm)",
y = "Body mass (kg)") +
theme(legend.position = c(0.9, 0.1))
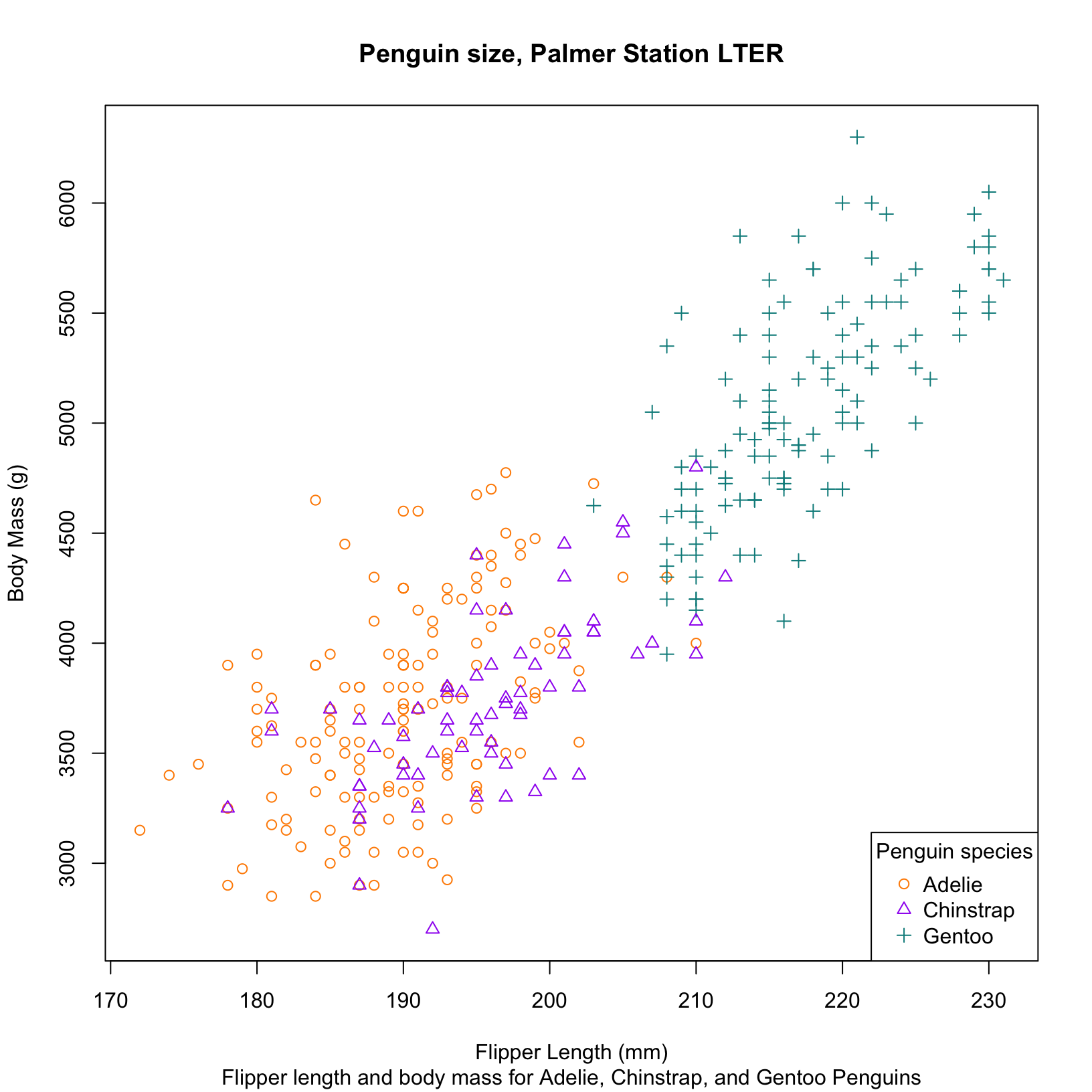
#Similar figure using base R
species_colors <- c("darkorange", "purple", "cyan4")
plot(penguins$flipper_length_mm, penguins$body_mass_g,
xlab = "Flipper Length (mm)", ylab = "Body Mass (g)",
main = "Penguin size, Palmer Station LTER",
sub = "Flipper length and body mass for Adelie, Chinstrap, and Gentoo Penguins",
pch = as.numeric(penguins$species), # Assign shapes based on species
col = species_colors[penguins$species]) # Assign colors based on species
# Add legend
legend("bottomright", legend = levels(penguins$species),
col = species_colors,
pch = 1:3, #shape codes to legend
title = "Penguin species")Time to practice!
In this section, you’ll have the chance to make more plots on your own. We’ll display different plots with several new features to try, and you can use your plotting and researching skills to recreate them. This is a great opportunity to experiment and be creative. Remember, questions are always welcome.
Numerical by categorical plots
Try making some numerical by categorical plots on your own using this dataset! This example looks at body mass in each species, using “jittered” points. See if you can recreate this on your own!
Hint – a reminder of the basic syntax for boxplots
# ggplot boxplot of body mass values in each species
ggplot(data = penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot(aes(color = species), width = 0.3) +
labs(x = "Species",
y = "Body mass (g)")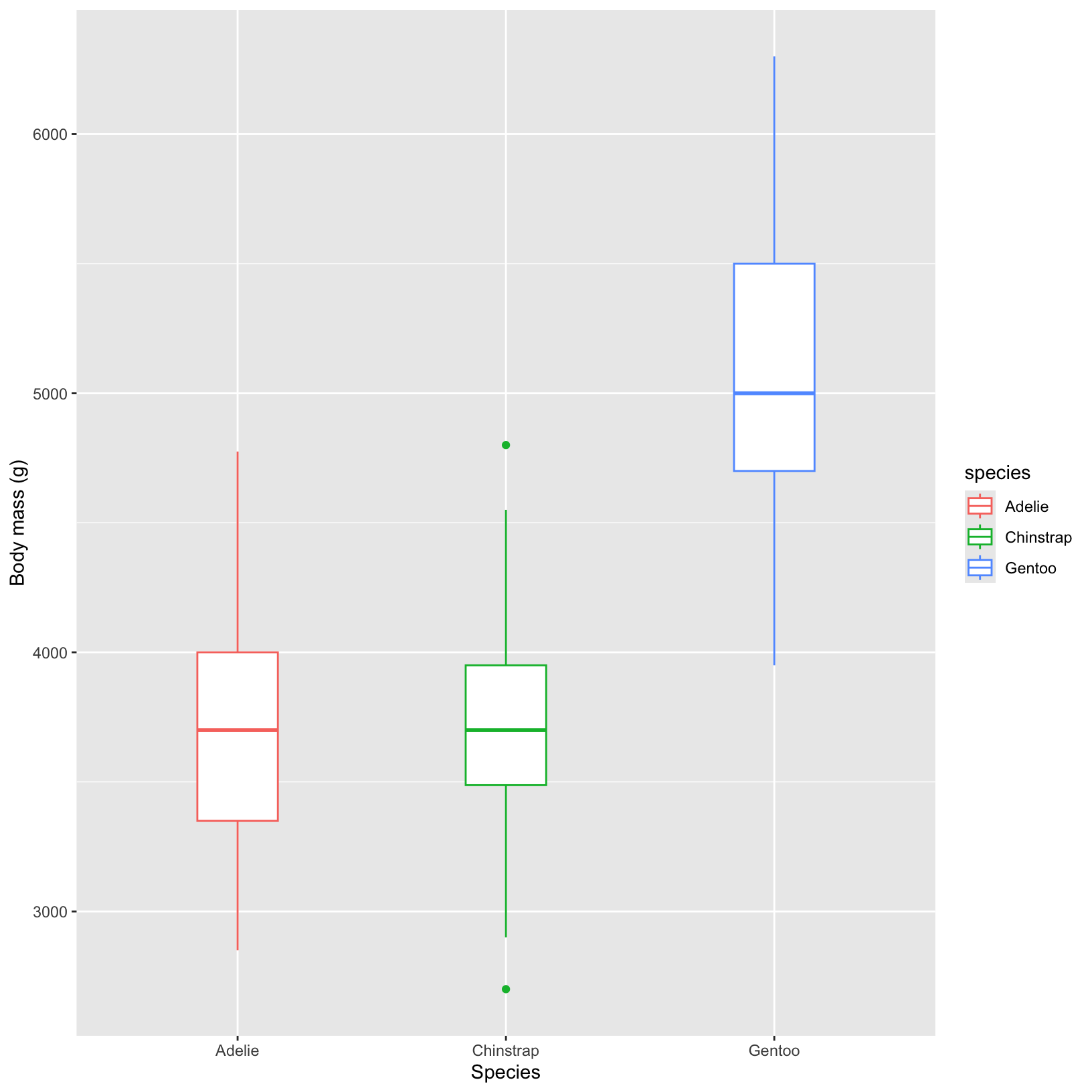
# Base R boxplot of body mass values in each species
boxplot(body_mass_g ~ species, data = penguins,
col = c("darkorange", "purple", "cyan4"),
main = "Body Mass by Penguin Species",
xlab = "Species",
ylab = "Body Mass (g)")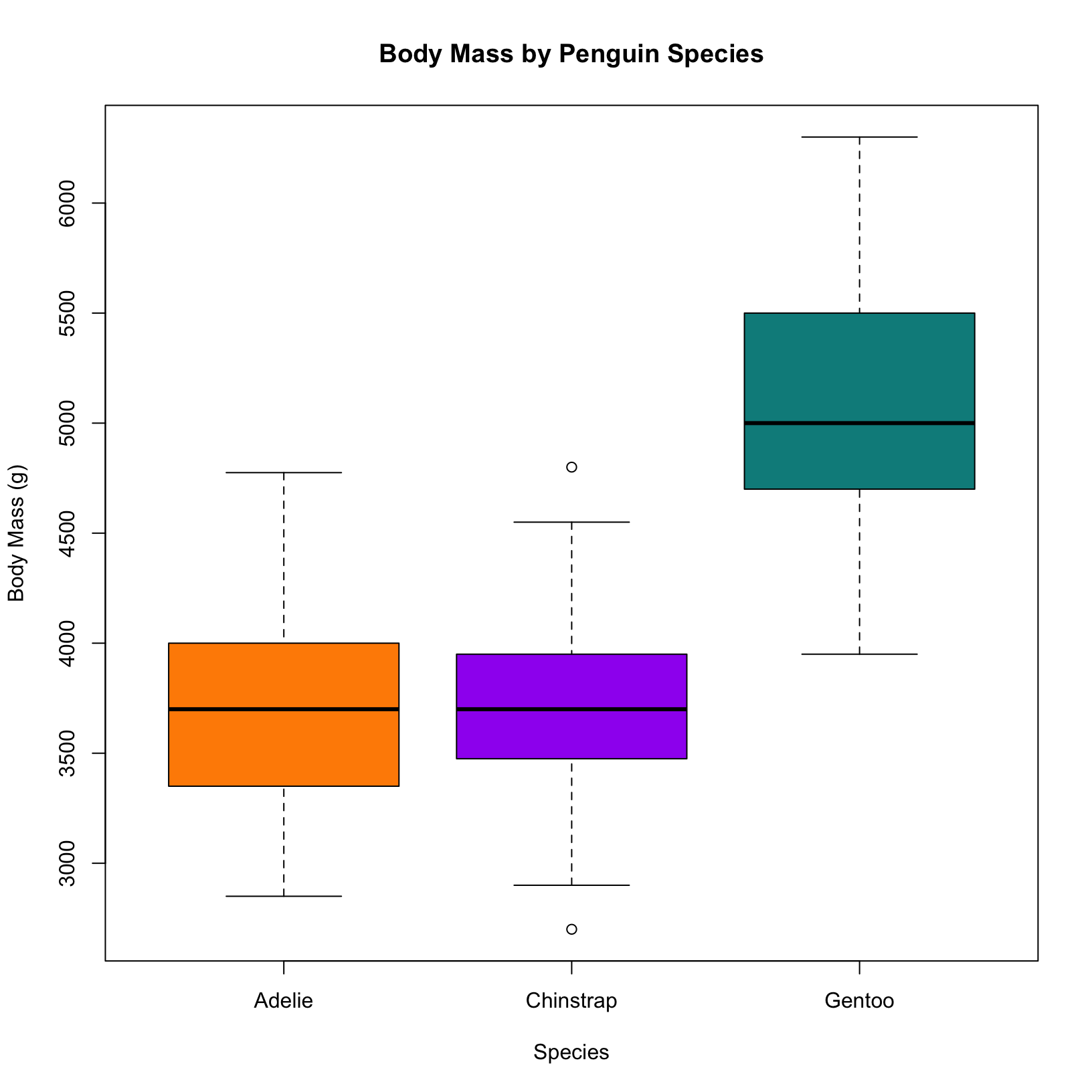
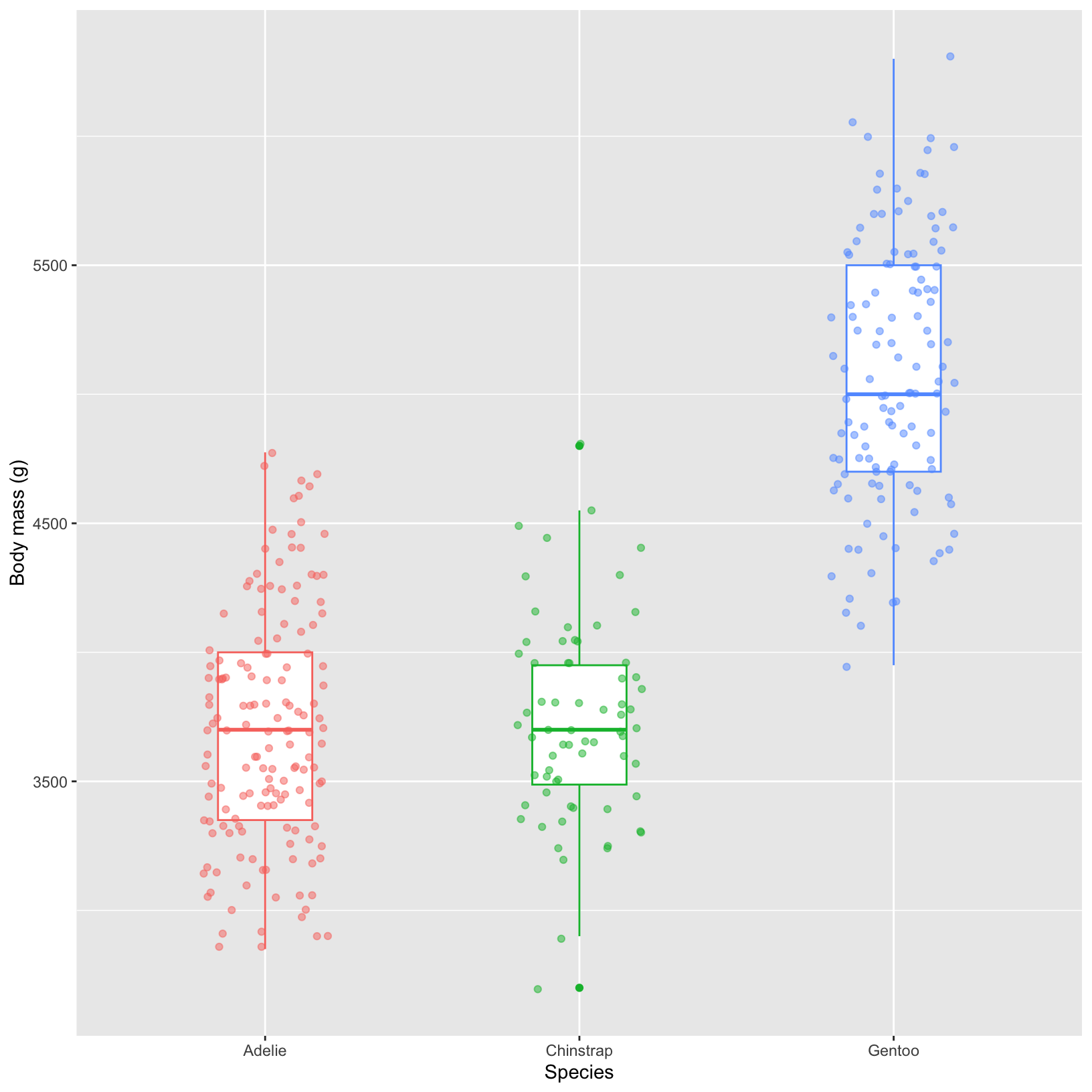
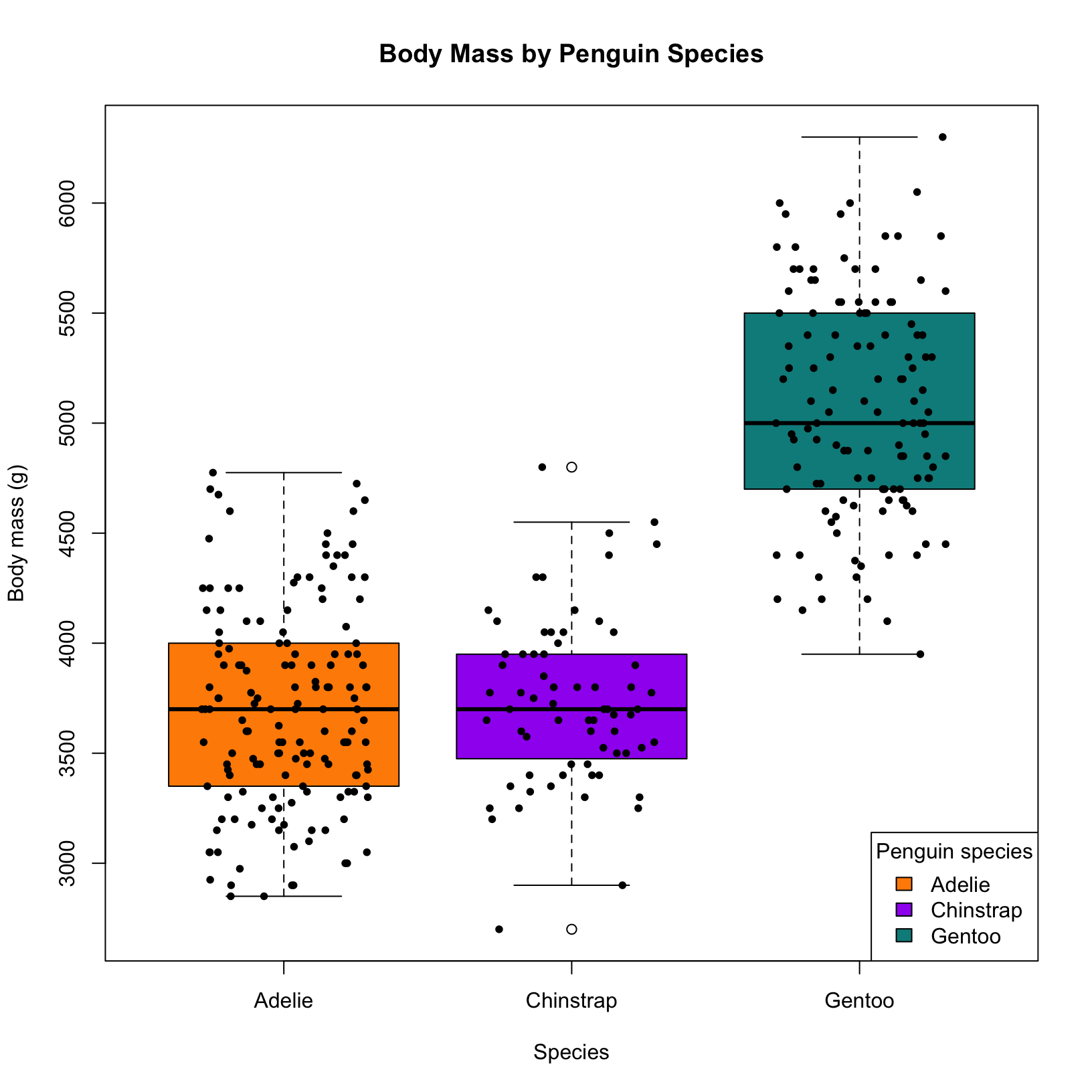
How to recreate this plot–try on your own first!
What if we also want to see individual points in a distribution? We can add points with “jitter” – a small amount of random variation on the x-axis – to better visualize where the points fall.
In ggplot2, you can use the geom_jitter() function to add jittered points to your plot. This adds a small amount of random noise to each point, making it easier to see overlapping points.
# overlay the raw data points using geom_jitter
ggplot(data = penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot(aes(color = species), width = 0.3, show.legend = FALSE) +
geom_jitter(aes(color = species), alpha = 0.5, show.legend = FALSE,
position = position_jitter(width = 0.2)) +
labs(x = "Species",
y = "Body mass (g)")In base R, you can achieve a similar effect using the jitter() function. This function adds a small amount of random variation to the data points, making overlapping points more distinguishable.
# Create the boxplot
boxplot(body_mass_g ~ species, data = penguins,
col = c("darkorange", "purple", "cyan4"),
main = "Body Mass by Penguin Species",
xlab = "Species",
ylab = "Body mass (g)")
# Add overlaid points (jittered). Factor controls the width of the points\
#cex controls their size, and pch controls the symbol
points(jitter(as.numeric(penguins$species), factor = 1.5),
penguins$body_mass_g,
pch = 16, cex = 0.8)
# Add custom legend (optional)
legend("bottomright", legend = levels(penguins$species),
fill = c("darkorange", "purple", "cyan4"),
title = "Penguin species")Plotting the distribution of a numerical variable
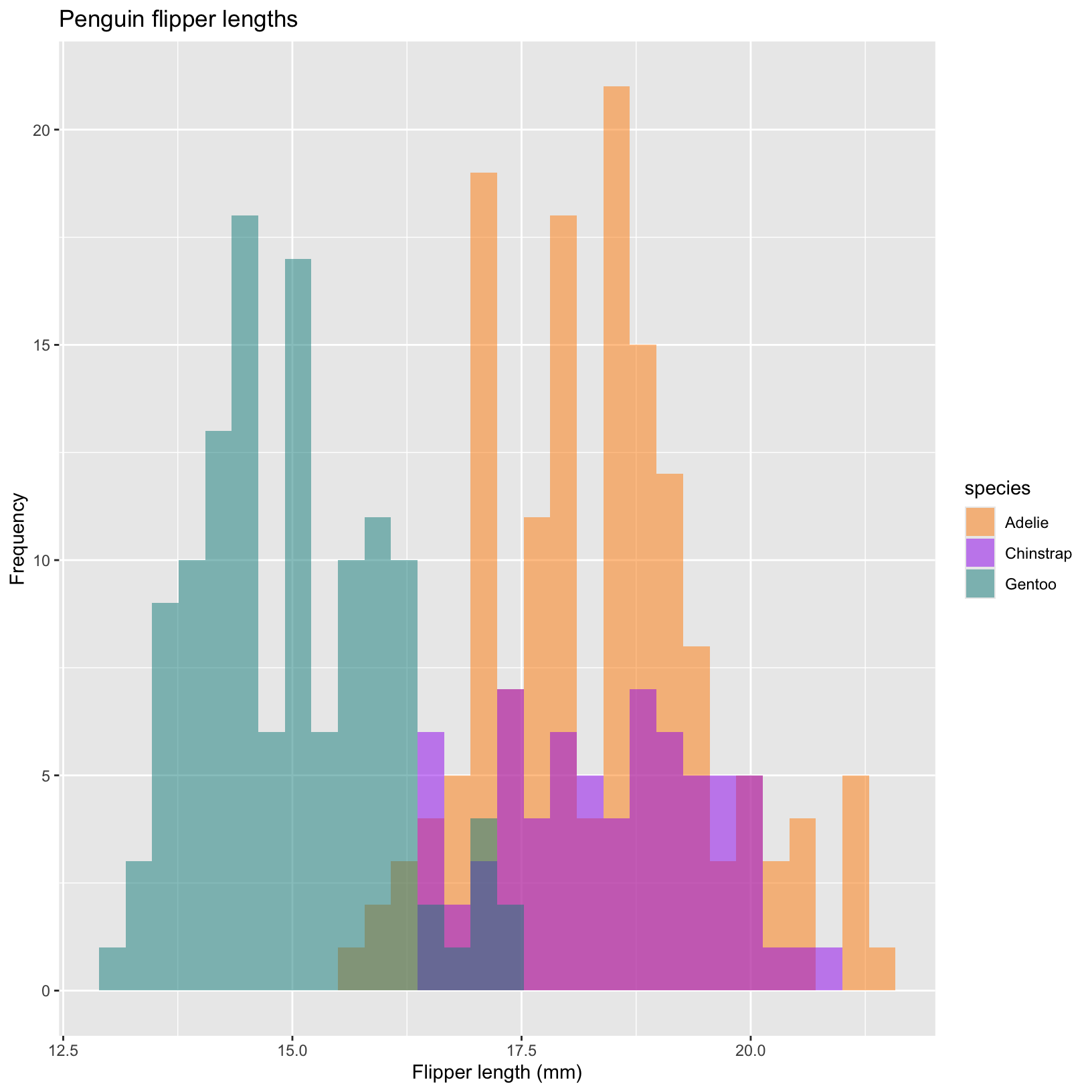
If we want to loot at the distribution of one numerical variable in detail, we could use a histogram. Here is an example of histograms that show us the distributions of each species, using new features like partially transparent colors and custom bar widths.
Hint – a reminder of the basic syntax for histograms
# a simple histogram of flipper length in ggplot
ggplot(data = penguins, aes(x = bill_depth_mm)) +
geom_histogram() 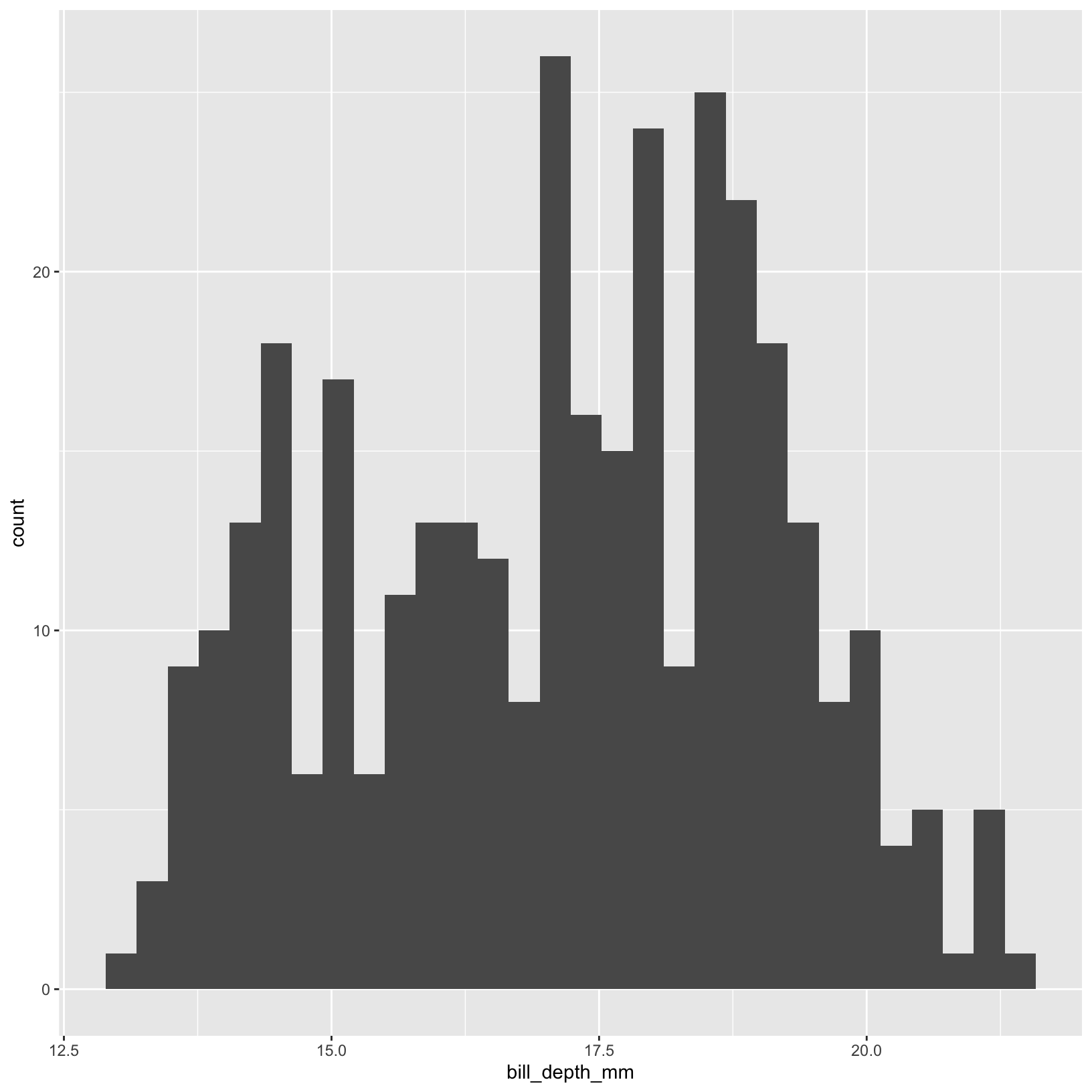
# simple histogram of flipper length
hist(penguins$bill_depth_mm, main = "Histogram of Penguin Bill Depth", xlab = "Bill Depth (mm)")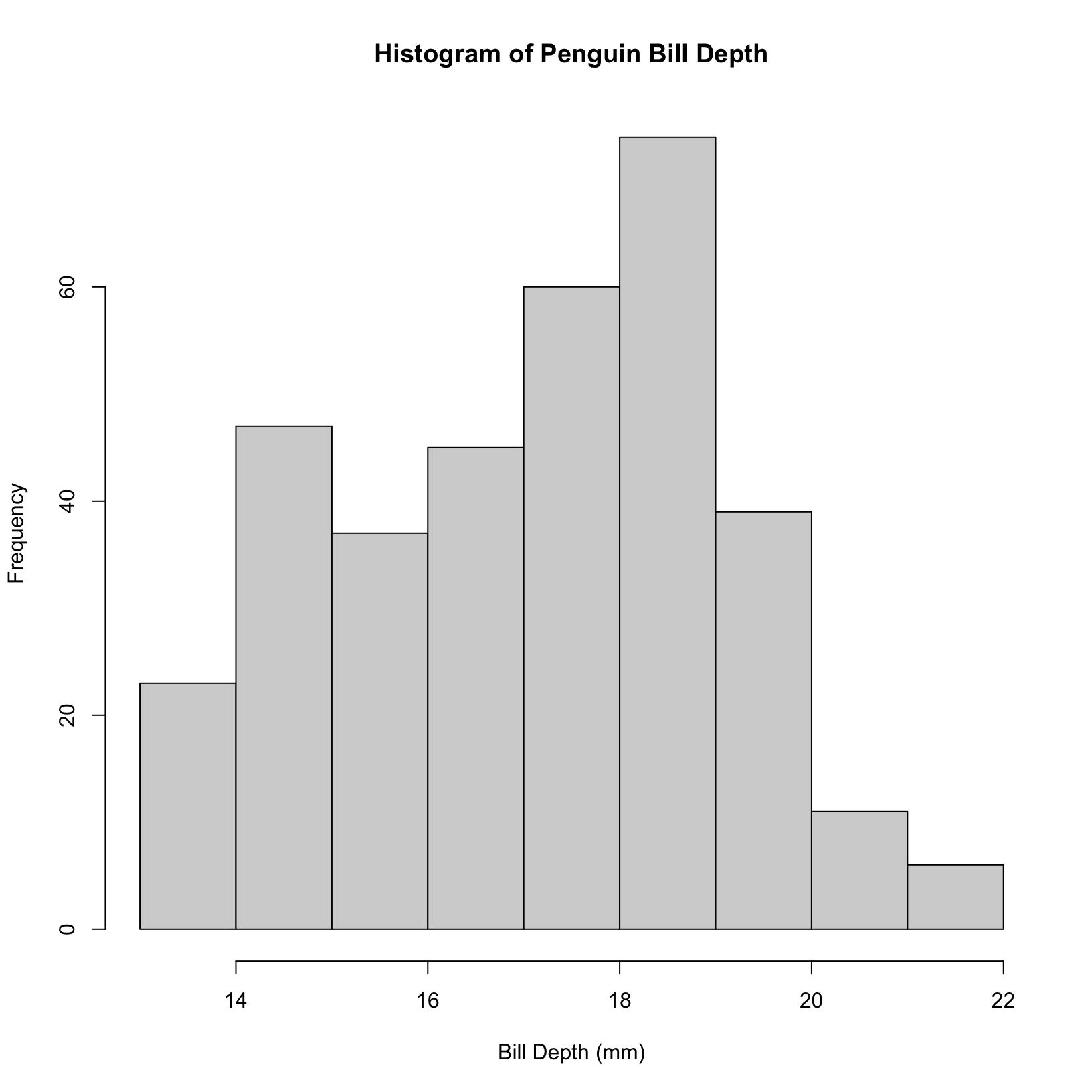
How do we change bin widths for histograms?
In ggplot2, you can change the number of bins in a histogram using the bins argument within the geom_histogram() function. Alternatively, you can use the binwidth argument to specify the width of each bin.
ggplot(data = penguins, aes(x = body_mass_g)) +
geom_histogram(bins = 30) +
labs(x = "Body Mass (g)", y = "Frequency")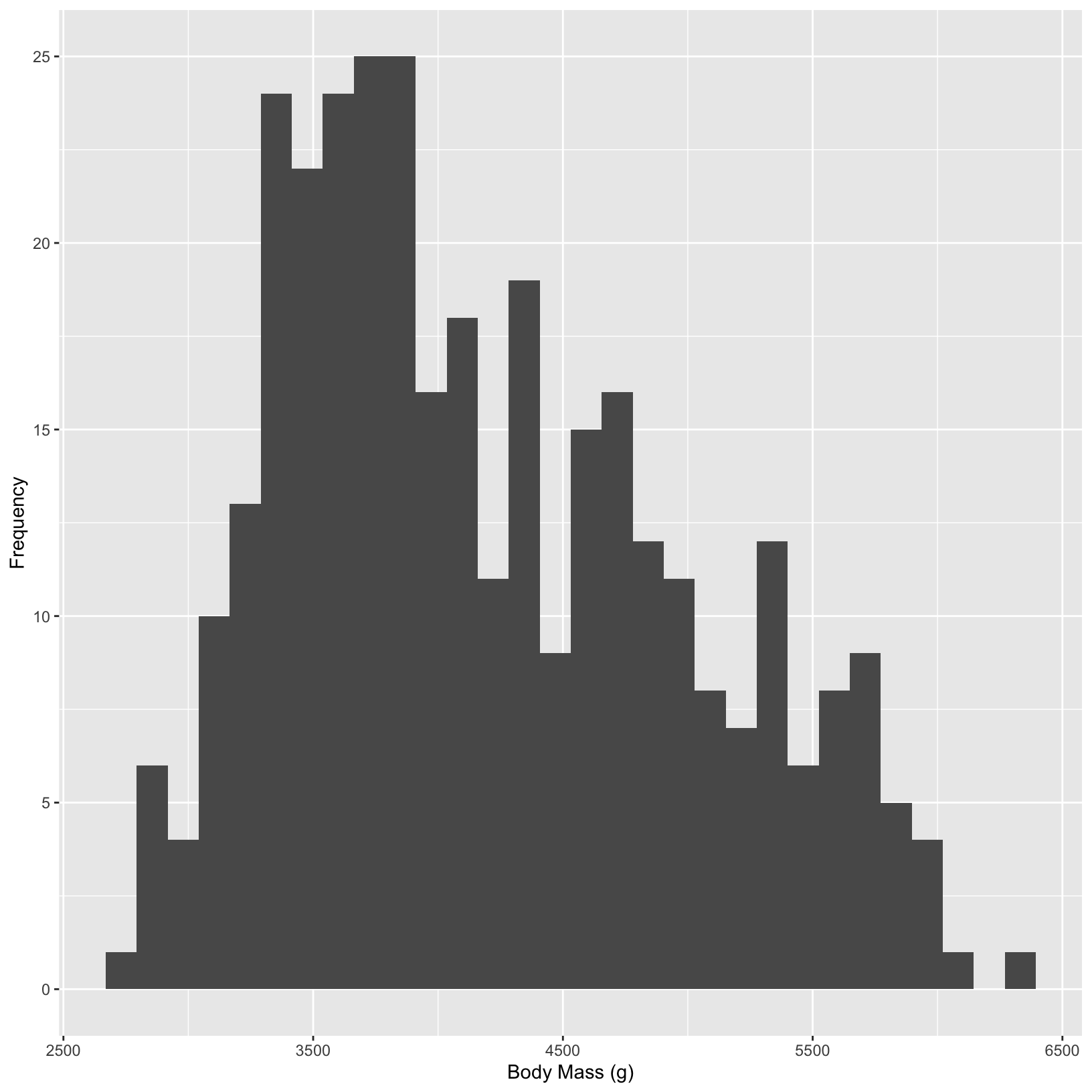
ggplot(data = penguins, aes(x = bill_depth_mm)) +
geom_histogram(binwidth=0.5) 
In base R, you can change the number of bins in a histogram using the breaks argument in the hist() function. This argument allows you to specify the number of bins directly, or you can pass a vector of break points.
#change the number of bins to your liking
hist(penguins$bill_depth_mm, breaks = 30, main = "Histogram of Penguin Bill Depth", xlab = "Bill Depth (mm)")
Challenge plot
Can we find the means of these distributions and plot the means on our histograms? Additionally, can we add text to clearly display the mean values on the plot?
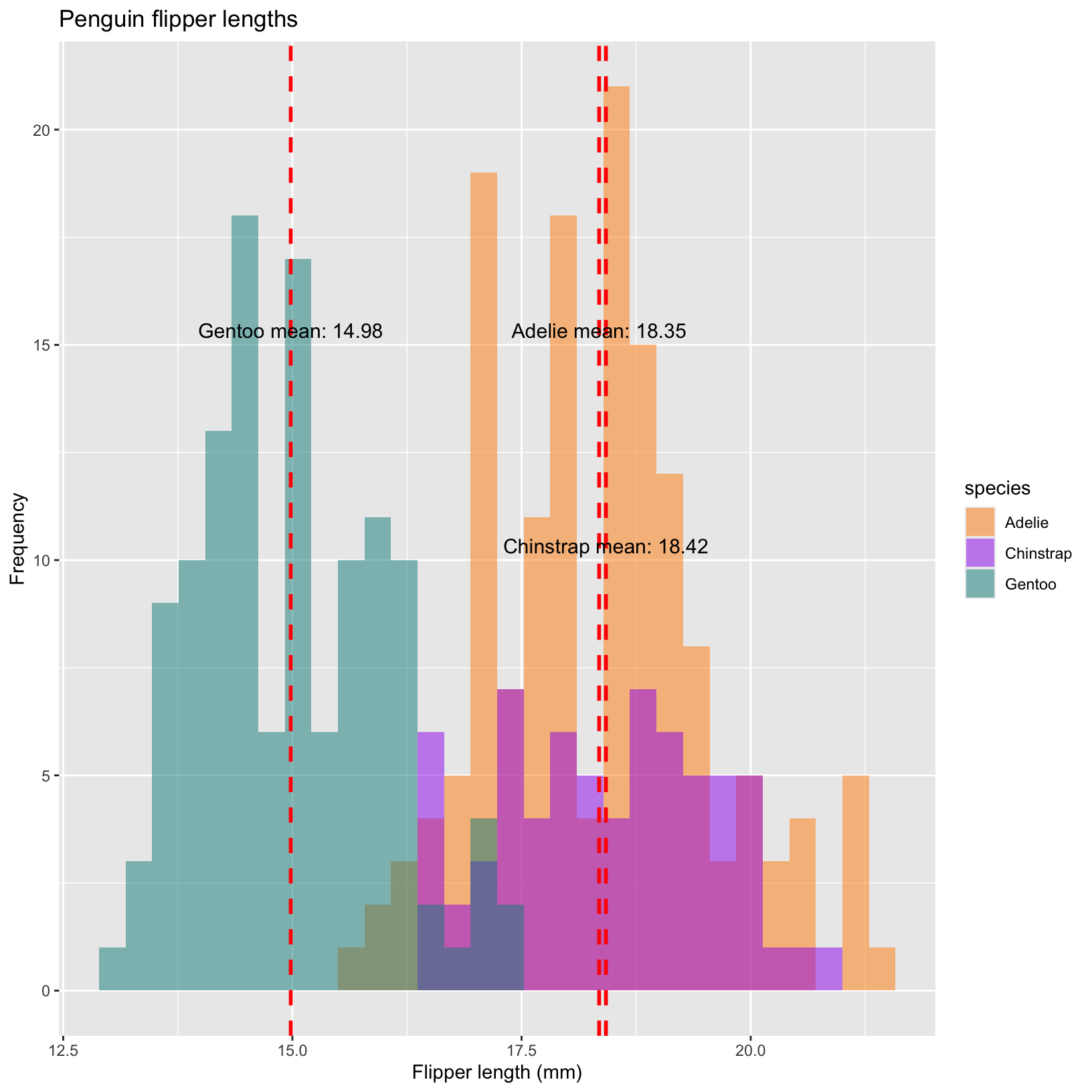
Code for this image
# Calculate the mean bill depth for each species
# This requires some skills we will learn in Week 3!
mean_depth <- penguins %>%
group_by(species) %>%
summarize(mean_bill_depth = mean(bill_depth_mm, na.rm = TRUE))
# add a line representing the mean to the histogram
ggplot(penguins, aes(x = bill_depth_mm, fill = species)) +
geom_histogram(aes(fill = species), alpha = 0.5, position = "identity") +
scale_fill_manual(values = c("darkorange","purple","cyan4")) +
labs(x = "Flipper length (mm)",
y = "Frequency",
title = "Penguin flipper lengths")+
geom_vline(data = mean_depth, aes(xintercept = mean_bill_depth),
color = "red", linetype = "dashed", linewidth = 1) +
geom_text(data = mean_depth, aes(x = mean_bill_depth, y = c(15,10,15),
label = paste(species, "mean:", round(mean_bill_depth, 2))),
color = "black", vjust = -0.5,
hjust = 0.5, size = 4) Mini-Lesson: Introduction to facet_grid in ggplot2
Background:
In data visualization, particularly when dealing with complex datasets, it’s beneficial to compare subsets of data across different categories simultaneously. ggplot2 provides various functions for creating faceted plots, with facet_grid being a prominent choice for creating grids that can help in exploring interactions between variables.
Faceting:
Faceting refers to the strategy of splitting one plot into multiple plots based on a factor (or factors) included in the dataset. Each plot represents a level of the factor(s) and shares the same axis scaling and grids, which makes them easy to compare.
The facet_grid function creates a matrix of panels defined by row and column faceting variables. The general syntax is:
facet_grid(rows ~ cols)If we just want to facet by rows or just by columns, replace that spot with a “.”.
#facet by rows
facet_grid(rows ~ .)
#facet by cols
facet_grid(. ~ cols)Lets take some of the plots we made earlier and facet them by the categorical variable year! Note that in some situations it makes more sense to facet by columns, and others by rows.
# Scatter plots with facet_grid
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species), size = 3) +
scale_color_manual(values = c("darkorange","purple","cyan4")) +
labs(title = "Penguin size, Palmer Station LTER",
subtitle = "Flipper length and body mass for Adelie, Chinstrap and Gentoo Penguins",
x = "Flipper length (cm)",
y = "Body mass (kg)",
color = "Penguin species",
shape = "Penguin species") +
theme(legend.position = c(0.9, 0.1), # x and y on a relative scale (0-1)
plot.title.position = "plot",
plot.caption = element_text(hjust = 0, face= "italic"),
plot.caption.position = "plot") +
facet_grid(. ~ island) 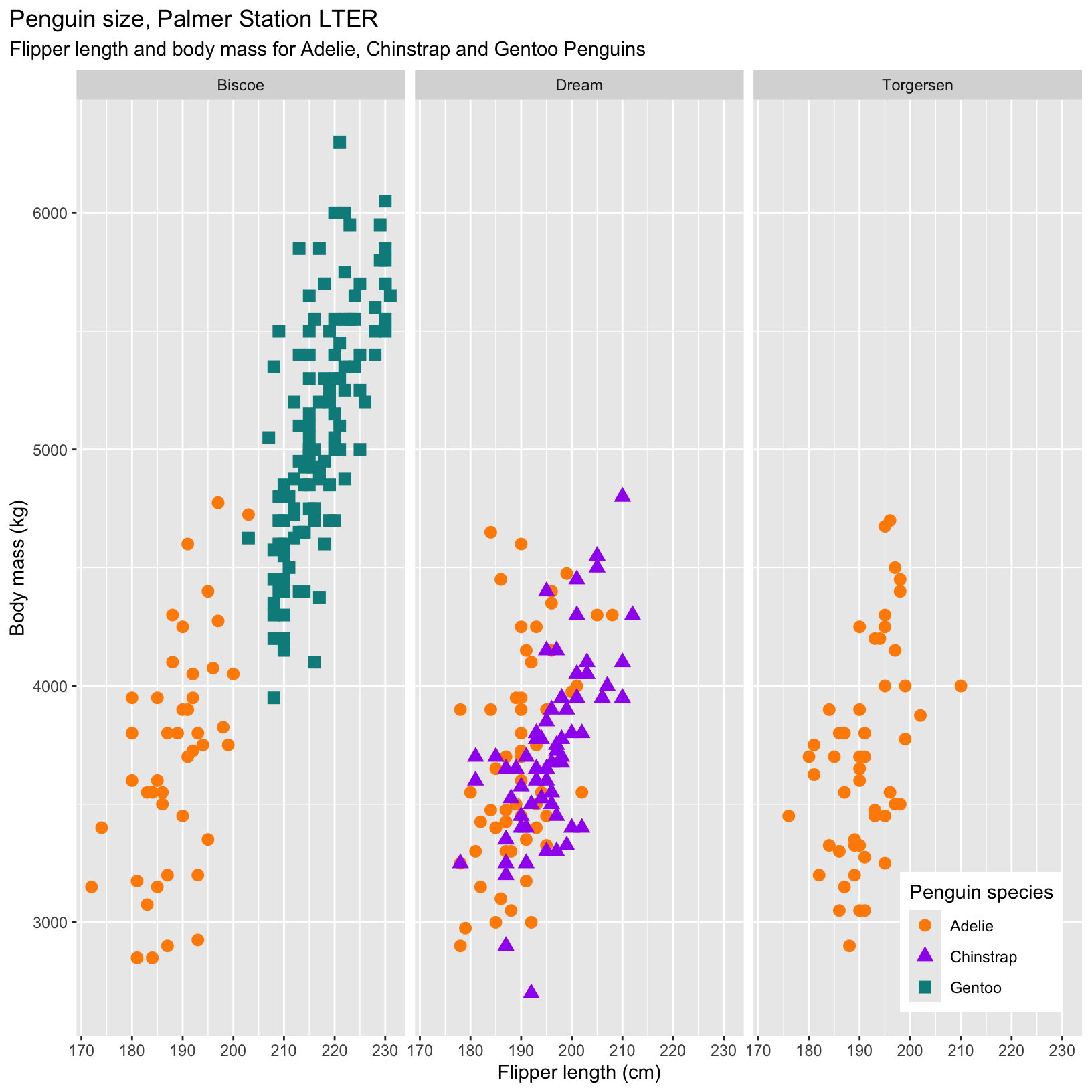
#Boxplots with facet_grid
ggplot(data = penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot(aes(color = species), width = 0.3, show.legend = FALSE) +
geom_jitter(aes(color = species), alpha = 0.5, show.legend = FALSE, position = position_jitter(width = 0.2)) +
labs(x = "Species",
y = "Body mass (g)") +
facet_grid(. ~ year) 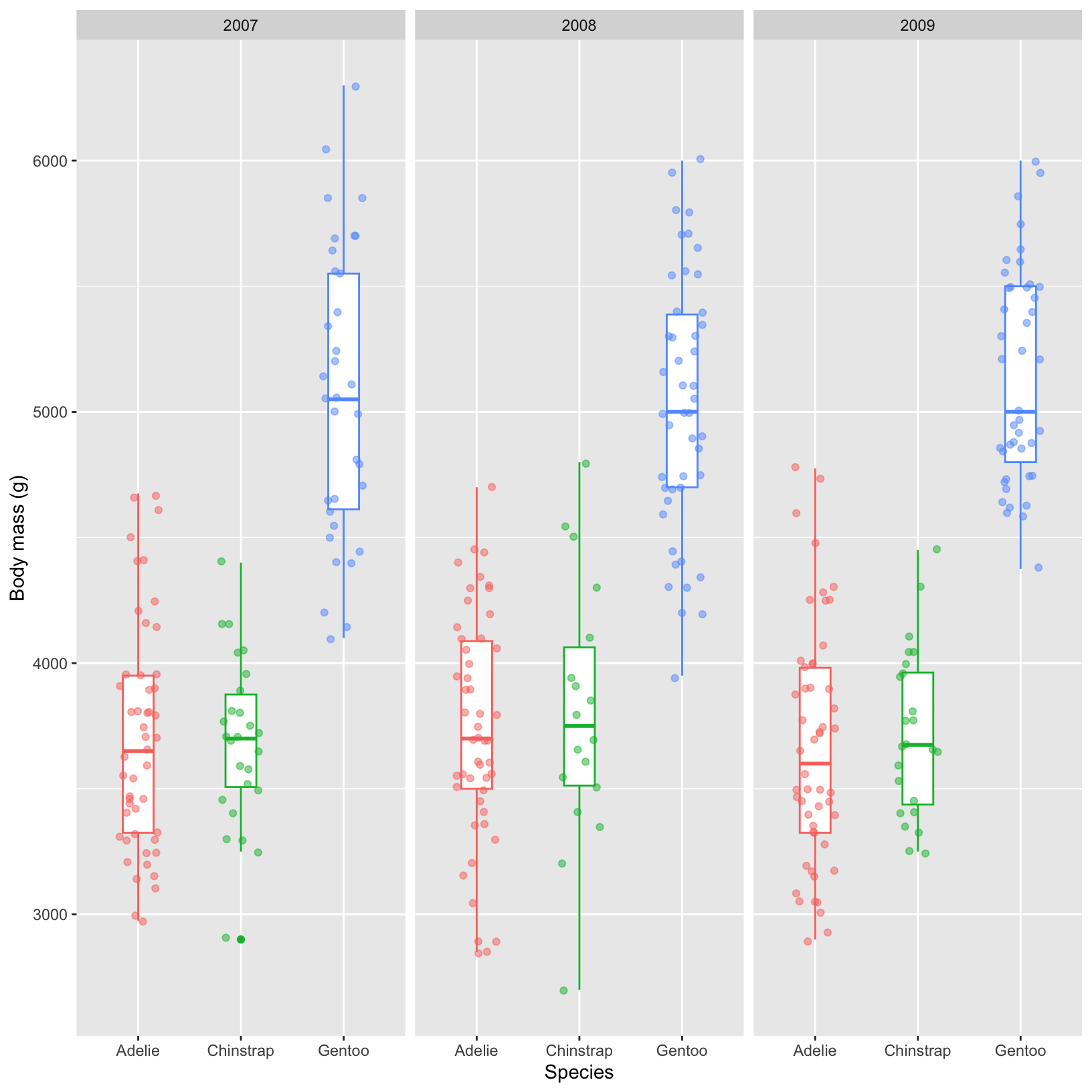
# Histograms with facet_grid for year
ggplot(penguins, aes(x = bill_depth_mm, fill = species)) +
geom_histogram(aes(fill = species),
alpha = 0.5,
position = "identity",
binwidth=0.5) +
scale_fill_manual(values = c("darkorange","purple","cyan4")) +
labs(x = "Flipper length (mm)",
y = "Frequency",
title = "Penguin flipper lengths")+
geom_vline(data = mean_depth, aes(xintercept = mean_bill_depth),
color = "red", linetype = "dashed", linewidth = 1) +
geom_text(data = mean_depth, aes(x = mean_bill_depth, y = c(10,7,5,10,7,5,10,7,5),
label = paste(species, "mean:", round(mean_bill_depth, 2))),
color = "black", vjust = -0.3, hjust = 0.5, size = 4) +
facet_grid(year ~ .) 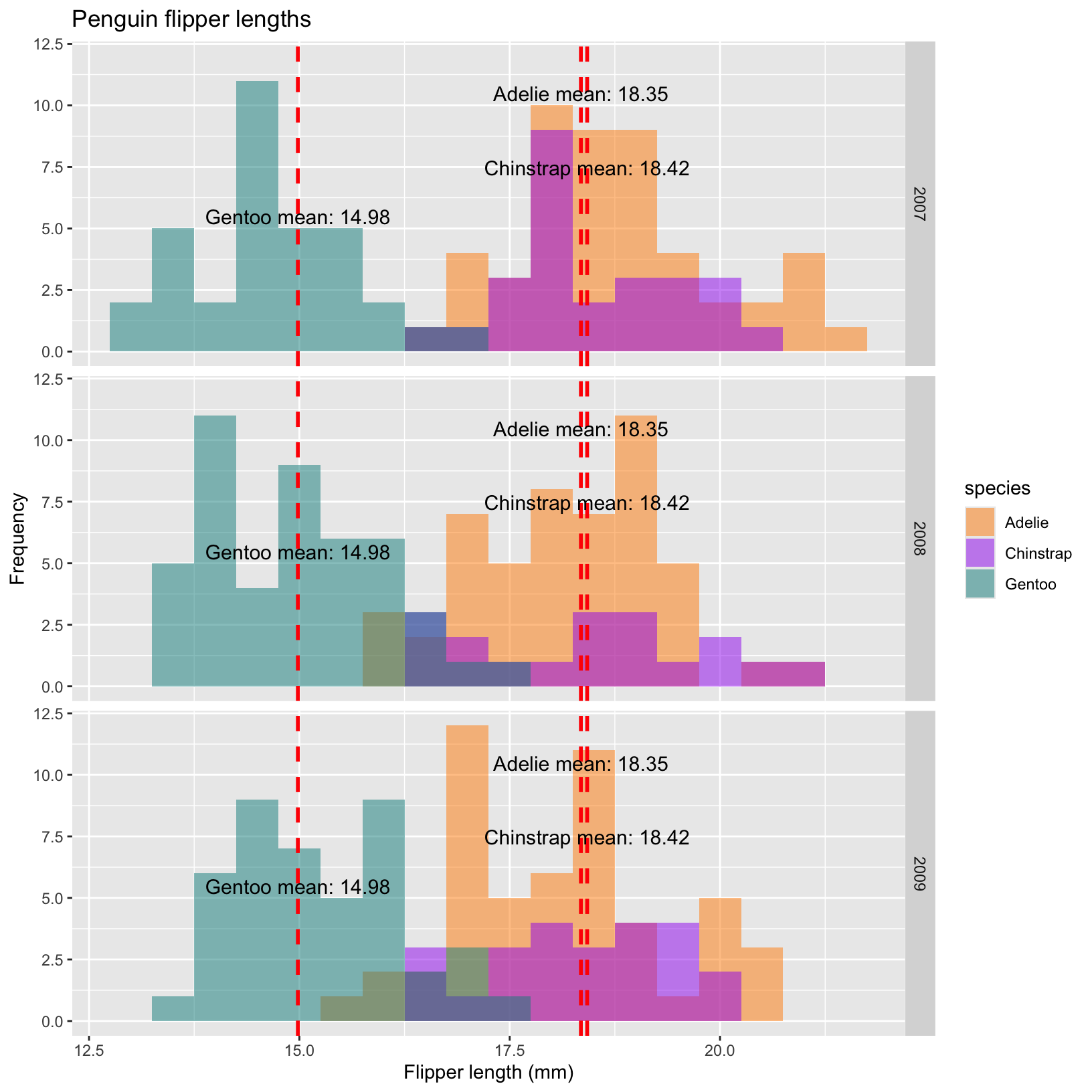
A useful package to make your plots colorblind friendly
Sometimes the plots we create are pretty, but our colorblind friends cannot see the relationships we are trying to show with them. The viridis package allows you to select from several beautiful colorblind friendly palettes and easily incorporate them into ggplots using scale_color_viridis().
#install.packages("viridis")
library(viridis)
# Scatter plots with facet_grid
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = flipper_length_mm, shape = species), size = 3) +
scale_color_viridis() + #scale_color_viridis_d is for discrete variables like species
labs(title = "Penguin size, Palmer Station LTER",
x = "Flipper length (cm)",
y = "Body mass (kg)",
color = "Flipper length",
shape = "Penguin species")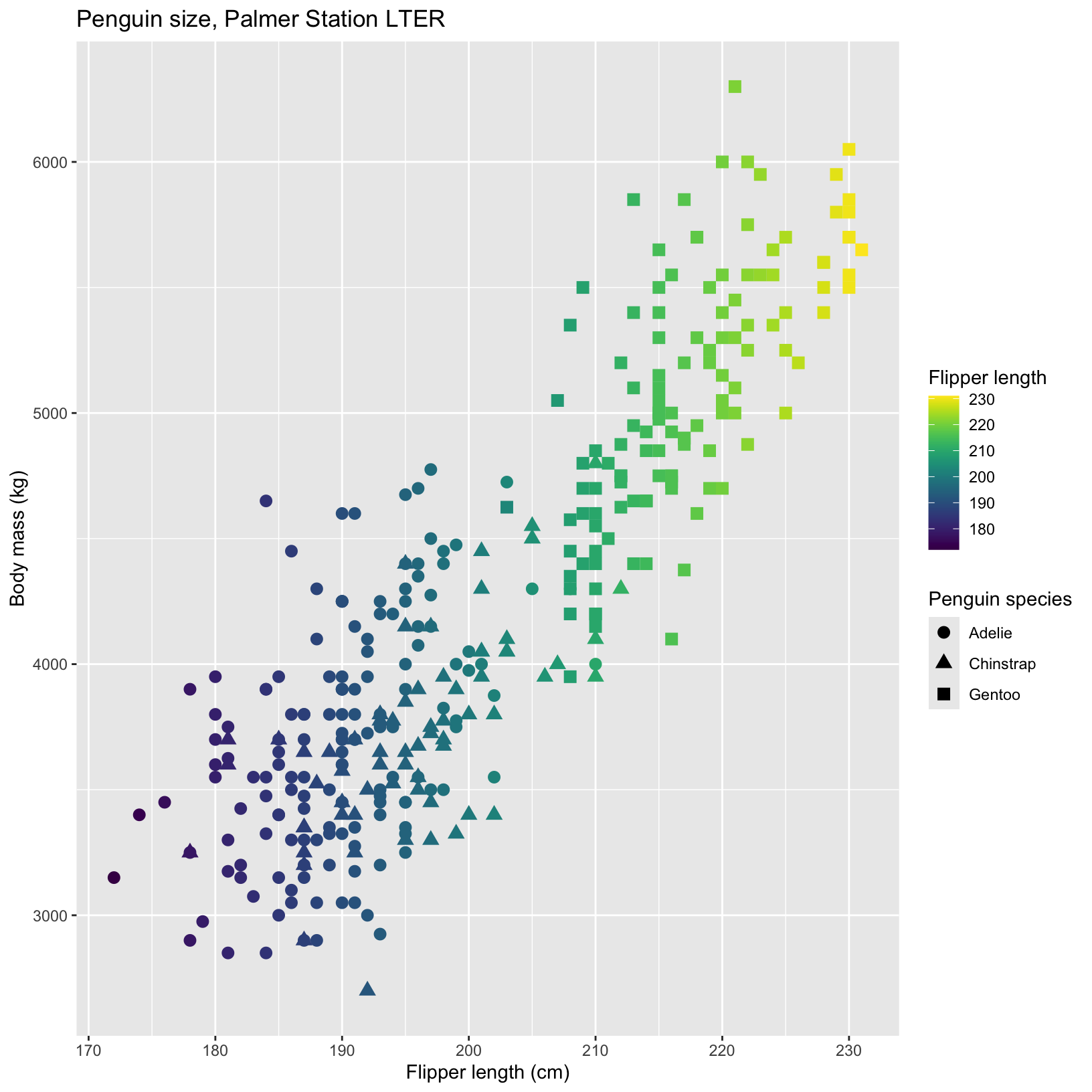
ggplot(data = penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species), size = 3) +
scale_color_viridis_d(option="plasma") + #try a new color scheme
labs(title = "Penguin size, Palmer Station LTER",
x = "Flipper length (cm)",
y = "Body mass (kg)",
color = "Penguin species",
shape = "Penguin species")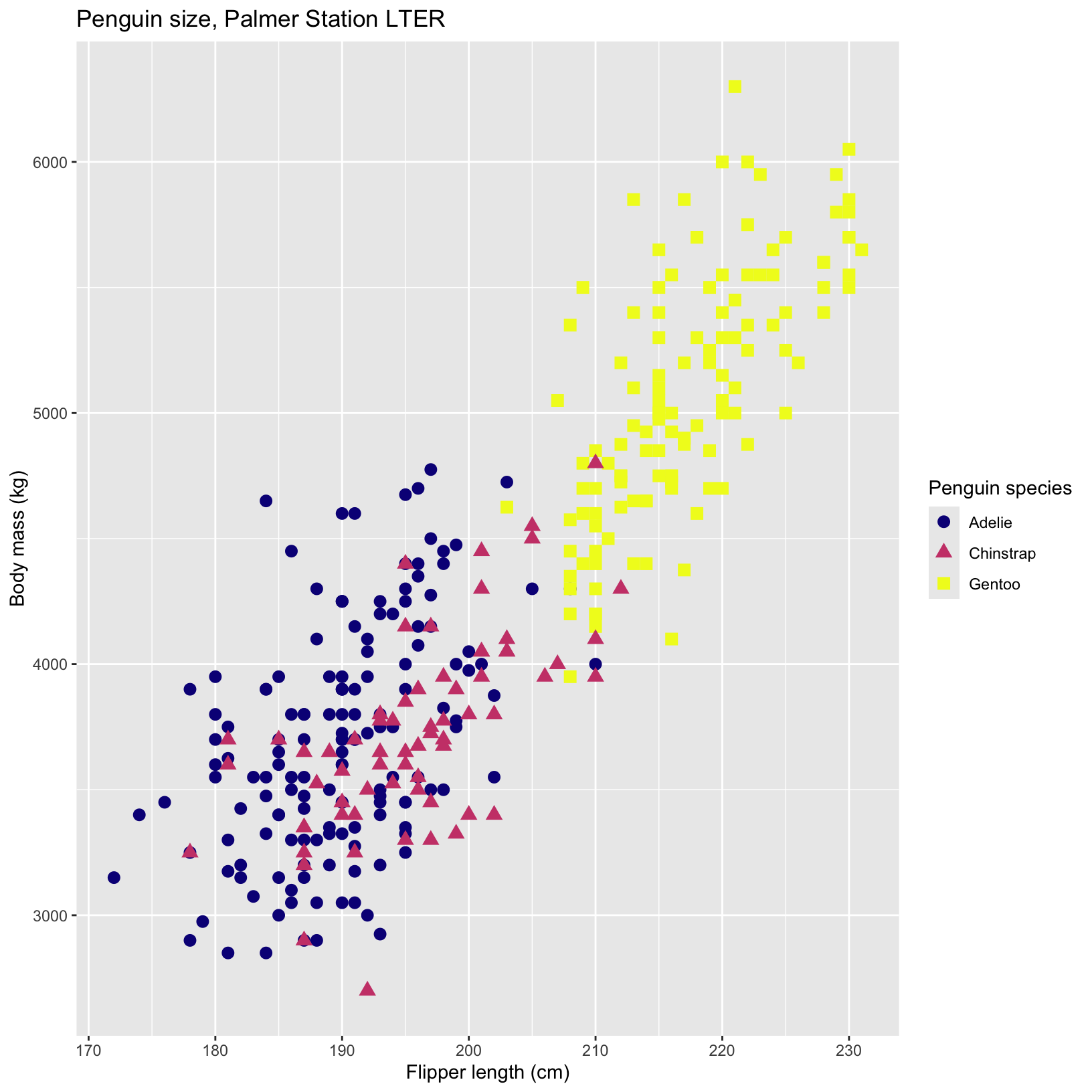
Conclusion
As we wrap up our exploration of data visualization, remember that the choices you make in your visualizations should be driven by the relationships you want to highlight in your data, while avoiding dishonest manipulation of the data. Before you start creating your plots, take a moment to think about what you want to understand or communicate about your data. This will guide your decisions on which aesthetics to use, how to customize your plots, and what story you want your data to tell.
Key Takeaways:
- Purpose-Driven Visualizations: Always have a clear idea of the relationships and insights you want to highlight with your data. This focus will help you make more intentional and impactful visualizations.
- Customization: Don’t be afraid to experiment with different aesthetics and customization options. Small tweaks can significantly enhance the clarity and appeal of your plots.
- Clarity and Simplicity: Aim for clarity in your visualizations. Make sure your plots are easy to read and interpret, with well-labeled axes, legends, and titles.
- Consistency: Maintain a consistent style across your visualizations to create a cohesive and professional look.
- Integrity: Ensure your visualizations are honest and accurate. Avoid manipulative practices that could mislead viewers or misrepresent the data.
Data visualization is both an art and a science. As you continue to practice and explore different techniques, you’ll develop a deeper understanding of how to effectively communicate your data insights. Keep experimenting, learning, and refining your skills.

Some useful, free resources
- Learn how to make almost any plot type in ggplot or base r: https://r-coder.com/
- Detailed description of ggplot functions by the authors: https://ggplot2.tidyverse.org/articles/ggplot2.html
- Take a deep dive on the theory behind ggplot2: https://ggplot2-book.org/
- A cookbook with basic set up and explanations for various plot types in base r and ggplot: https://r-graphics.org/.
- Friends Don’t Let Friends Make Bad Graphs: https://github.com/cxli233/FriendsDontLetFriends